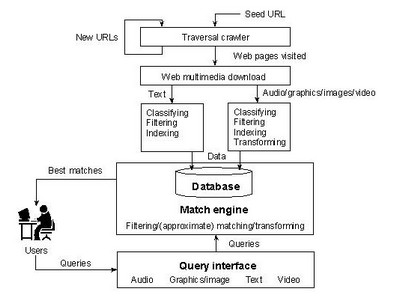
Search engines consist of three components: (i) web crawlers, (ii) web page indexing, and (iii) search and ranking software.
Web Crawlers/Spiders
Web crawlers are programs that automatically scans various web sites.
Crawlers follow the links on a site to find other relevant pages.
Two search algorithms are widely used by crawlers to traverse the Web:
|
|
Web Page Indexing
Automatic indexing is the process of algorithmically examining information items to build a data structure that can be quickly searched. B-trees and inverted files are two common data structures for information retrieval. This component creates indexes for URLs by using keywords, links, titles, etc.
Search and Ranking Software
When a user submits a search query, the engine’s software goes through the indexes to find web pages with keyword matching and ranks the pages in terms of relevance.
Search engines are different from information retrieval systems because of the runtime requirement. The huge amount of web data causes most indexing methods obsolete for search engines.
|
“Your conscience is the measure of the honesty of your selfishness. Listen to it carefully.” ― Richard Bach, Illusions: The Adventures of a Reluctant Messiah |