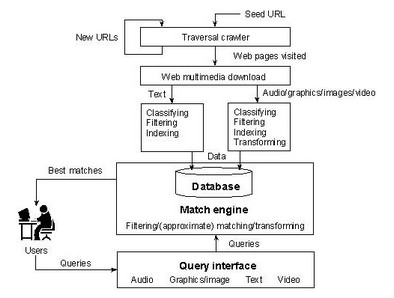
The first programming exercise is related to the construction of a web search engine, which includes the following three components:
|
|
- Indexing software
- Automatic indexing is the process of algorithmically examining information items to build a data structure that can be quickly searched.
- Search and ranking software
- This software analyzes a query and compares it to the indexes to find and determine in which order to display the relevant pages.
|
A ballpark figure (a rough estimate) for the cost of the new stadium would be $150,000,000. |