


Depto. de Ciencias de la Computación, Universidad de Chile, Casilla 2777, Santiago, Chile
Abstract
In this chapter we review the main concepts and data structures used in information retrieval, and we classify information retrieval related algorithms.
Infomation retrieval (IR) is a multidisciplinary field. In this chapter we study data structures and algorithms used in the implementation of IR systems. In this sense, many contributions from theoretical computer science have practical and regular use in IR systems.
The first section covers some basic concepts: strings, regular expressions, and finite automata. In section 2.3 we have a look at the three classical foundations of structuring data in IR: search trees, hashing, and digital trees. We give the main performance measures of each structure and the associated trade-offs. In section 2.4 we attempt to classify IR algorithms based on their actions. We distinguish three main classes of algorithms and give examples of their use. These are retrieval, indexing, and filtering algorithms.
The presentation level is introductory, and assumes some programming knowledge as well as some theoretical computer science background. We do not include code bccause it is given in most standard textbooks. For good C or Pascal code we suggest the Handbook of Algorithms and Data Structures of Gonnet and Baeza-Yates (1991).
We start by reviewing basic concepts related with text: strings, regular expressions (as a general query language), and finite automata (as the basic text processing machine). Strings appear everywhere, and the simplest model of text is a single long string. Regular expressions provide a powerful query language, such that word searching or Boolean expressions are particular cases of it. Finite automata are used for string searching (either by software or hardware), and in different ways of text filtering and processing.
We use
When manipulating strings, we need to know how similar are a pair of strings. For this purpose, several similarity measures have been defined. Each similarity model is defined by a distance function d, such that for any strings s1, s2, and s3, satisfies the following properties:
The two main distance functions are as follows:
We use the usual definition of regular expressions (RE for short) defined by the operations of concatenation, union (+) and star or Kleene closure (*) (Hopcroft and Ullman (1979). A language over an alphabet
We use L(r) to represent the set of strings in the language denoted by the regular expression r. The regular expressions over
To avoid unnecessary parentheses we adopt the convention that the star operator has the highest precedence, then concatenation, then union. All operators are left associative.
We also use:
Examples:
All the examples given here arise from the Oxford English Dictionary:
1. All citations to an author with prefix Scot followed by at most 80 arbitrary characters then by works beginning with the prefix Kenilw or Discov:
where< > are characters in the OED text that denote tags (A for author, W for work).
2. All "bl" tags (lemma in bold) containing a single word consisting of lowercase alphabetical only:
3. All first citations accredited to Shakespeare between 1610-11:
where EQ stands for the earliest quotation tag, LQ for quotation label, Q for the quotation itself, and D for date.
4. All references to author W. Scott:
where b denotes a literal space.
We use regular languages as our query domain, and regular languages can be represented by regular expressions. Sometimes, we restrict the query to a subset of regular languages. For example, when searching in plain text, we have the exact string matching problem, where we only allow single strings as valid queries.
A finite automaton is a mathematical model of a system. The automaton can be in any one of a finite number of states and is driven from state to state by a sequence of discrete inputs. Figure 2.1 depicts an automaton reading its input from a tape.
Formally, a finite automaton (FA) is defined by a 5-tuple (Q,
A finite automaton starts in state q0 reading the input symbols from a tape. In one move, the FA in state q and reading symbol a enters state(s)
The languages accepted by finite automata (either DFAs or NFAs) are regular languages. In other words, there exists a FA that accepts L(r) for any regular expression r; and given a DFA or NFA, we can express the language that it recognizes as RE. There is a simple algorithm that, given a regular expression r, constructs a NFA that accepts L (r) in O (|r|) time and space. There are also algorithms to convert a NFA to a NFA without
Figure 2.2 shows the DFA that searches an occurrence of the fourth query of the previous section in a text. The double circled state is the final state of the DFA. All the transitions are shown with the exception of
A DFA is called minimal if it has the minimum possible number of states. There exists an O(|
A finite automaton is called partial if the
DFA will be used in this book as searching machines. Usually, the searching time depends on how the transitions are implemented. If the alphabet is known and finite, using a table we have constant time per transition and thus O (n) searching time. If the alphabet is not known in advance, we can use an ordered table in each state. In this case, the searching time is O (n log m). Another possibility would be to use a hashing table in each state, achieving constant time per transition on average.
In this section we cover three basic data structures used to organize data: search trees, digital trees, and hashing. They are used not only for storing text in secondary memory, but also as components in searching algorithms (especially digital trees). We do not describe arrays, because they are a well-known structure that can be used to implement static search tables, bit vectors for set manipulation, suffix arrays (Chapter 5), and so on.
These three data structures differ on how a search is performed. Trees define a lexicographical order over the data. However, in search trees, we use the complete value of a key to direct the search, while in digital trees, the digital (symbol) decomposition is used to direct the search. On the other hand, hashing "randomizes" the data order, being able to search faster on average, with the disadvantage that scanning in sequential order is not possible (for example, range searches are expensive).
Some examples of their use in subsequent chapters of this book are:
We refer the reader to Gonnet and Baeza-Yates (1991) for search and update algorithms related to the data structures of this section.
The most well-known search tree is the binary search tree. Each internal node contains a key, and the left subtree stores all keys smaller that the parent key, while the right subtree stores all keys larger than the parent key. Binary search trees are adequate for main memory. However, for secondary memory, multiway search trees are better, because internal nodes are bigger. In particular, we describe a special class of balanced multiway search trees called B-tree.
A B-tree of order m is defined as follows:
Usually, a B-tree is used as an index, and all the associated data are stored in the leaves or buckets. This structure is called B+-tree. An example of a B+-tree of order 2 is shown in Figure 2.3, using bucket size 4.
B-trees are mainly used as a primary key access method for large databases in secondary memory. To search a given key, we go down the tree choosing the appropriate branch at each step. The number of disk accesses is equal to the height of the tree.
Updates are done bottom-up. To insert a new record, we search the insertion point. If there is not enough space in the corresponding leaf, we split it, and we promote a key to the previous level. The algorithm is applied recursively, up to the root, if necessary. In that case, the height of the tree increases by one. Splits provides a minimal storage utilization of 50 percent. Therefore, the height of the tree is at most logm+1(n/b) + 2 where n is the number of keys, and b is the number of records that can be stored in a leaf. Deletions are handled in a similar fashion, by merging nodes. On average, the expected storage utilization is ln 2
To improve storage utilization, several overflow techniques exist. Some of them are:
A special kind of B-trees, Prefix B-trees (Bayer and Unterauer 1977), supports efficiently variable length keys, as is the case with words. This kind of B-tree is discussed in detail in Chapter 3.
A hashing function h (x) maps a key x to an integer in a given range (for example, 0 to m - 1). Hashing functions are designed to produce values uniformly distributed in the given range. For a good discussion about choosing hashing functions, see Ullman (1972), Knuth (1973), and Knott (1975). The hashing value is also called a signature.
A hashing function is used to map a set of keys to slots in a hashing table. If the hashing function gives the same slot for two different keys, we say that we have a collision. Hashing techniques mainly differ in how collisions are handled. There are two classes of collision resolution schemas: open addressing and overflow addressing.
In open addressing (Peterson 1957), the collided key is "rehashed" into the table, by computing a new index value. The most used technique in this class is double hashing, which uses a second hashing function (Bell and Kaman 1970; Guibas and Szemeredi 1978). The main limitation of this technique is that when the table becomes full, some kind of reorganization must be done. Figure 2.4 shows a hashing table of size 13, and the insertion of a key using the hashing function h (x) = x mod 13 (this is only an example, and we do not recommend using this hashing function!).
In overflow addressing (Williams 1959; Knuth 1973), the collided key is stored in an overflow area, such that all key values with the same hashing value are linked together. The main problem of this schema is that a search may degenerate to a linear search.
Searches follow the insertion path until the given key is found, or not (unsuccessful case). The average search time is constant, for nonfull tables.
Because hashing "randomizes" the location of keys, a sequential scan in lexicographical order is not possible. Thus, ordered scanning or range searches are very expensive. More details on hashing can be found in Chapter 13.
Hashing schemes have also been used for secondary memory. The main difference is that tables have to grow dynamically as the number of keys increases. The main techniques are extendible hashing which uses hashing on two levels: a directory and a bucket level (Fagin et al. 1979), and linear hashing which uses an overflow area, and grows in a predetermined way (Litwin 1980; Larson 1980; Larson and Kajla 1984). For the case of textual databases, a special technique called signature files (Faloutsos 1987) is used most frequently. This technique is covered in detail in Chapter 4 of this book.
To improve search time on B-trees, and to allow range searches in hashing schemes, several hybrid methods have been devised. Between them, we have to mention the bounded disorder method (Litwin and Lomet 1987), where B+-tree buckets are organized as hashing tables.
Efficient prefix searching can be done using indices. One of the best indices for prefix searching is a binary digital tree or binary trie constructed from a set of substrings of the text. This data structure is used in several algorithms.
Tries are recursive tree structures that use the digital decomposition of strings to represent a set of strings and to direct the searching. Tries were invented by de la Briandais (1959) and the name was suggested by Fredkin (1960), from information retrie val. If the alphabet is ordered, we have a lexicographically ordered tree. The root of the trie uses the first character, the children of the root use the second character, and so on. If the remaining subtrie contains only one string, that string's identity is stored in an external node.
Figure 2.5 shows a binary trie (binary alphabet) for the string "01100100010111 . . . " after inserting all the substrings that start from positions 1 through 8. (In this case, the substring's identity is represented by its starting position in the text.)
The height of a trie is the number of nodes in the longest path from the root to an external node. The length of any path from the root to an external node is bounded by the height of the trie. On average, the height of a trie is logarithmic for any square-integrable probability distribution (Devroye 1982). For a random uniform distribution (Regnier 1981), we have
for a binary trie containing n strings.
The average number of internal nodes inspected during a (un)successful search in a binary trie with n strings is log2n + O(1). The average number of internal nodes is
A Patricia tree (Morrison 1968) is a trie with the additional constraint that single-descendant nodes are eliminated. This name is an acronym for "Practical Algorithm To Retrieve Information Coded In Alphanumerical." A counter is kept in each node to indicate which is the next bit to inspect. Figure 2.6 shows the Patricia tree corresponding to the binary trie in Figure 2.5.
For n strings, such an index has n external nodes (the n positions of the text) and n -1 internal nodes. Each internal node consists of a pair of pointers plus some counters. Thus, the space required is O(n).
It is possible to build the index in
A trie built using the substrings (suffixes) of a string is also called suffix tree (McCreight [1976] or Aho et al. [1974]). A variation of these are called position trees (Weiner 1973). Similarly, a Patricia tree is called a compact suffix tree.
It is hard to classify IR algorithms, and to draw a line between each type of application. However, we can identify three main types of algorithms, which are described below.
There are other algorithms used in IR that do not fall within our description, for example, user interface algorithms. The reason that they cannot be considered as IR algorithms is because they are inherent to any computer application.
The main class of algorithms in IR is retrieval algorithms, that is, to extract information from a textual database. We can distinguish two types of retrieval algorithms, according to how much extra memory we need:
Formally, we can describe a generic searching problem as follows: Given a string t (the text), a regular expression q (the query), and information (optionally) obtained by preprocessing the pattern and/or the text, the problem consists of finding whether t
1. The location where an occurrence (or specifically the first, the longest, etc.) of q exists. Formally, if t
2. The number of occurrences of the pattern in the text. Formally, the number of all possible values of m in the previous category.
3. All the locations where the pattern occurs (the set of all possible values of m).
In general, the complexities of these problems are different.
We assume that
The efficiency of retrieval algorithms is very important, because we expect them to solve on-line queries with a short answer time. This need has triggered the implementation of retrieval algorithms in many different ways: by hardware, by parallel machines, and so on. These cases are explained in detail in Chapter 17 (algorithms by hardware) and Chapter 18 (parallel algorithms).
This class of algorithms is such that the text is the input and a processed or filtered version of the text is the output. This is a typical transformation in IR, for example to reduce the size of a text, and/or standardize it to simplify searching.
The most common filtering/processing operations are:
Unfortunately, these filtering operations may also have some disadvantages. Any query, before consulting the database, must be filtered as is the text; and, it is not possible to search for common words, special symbols, or uppercase letters, nor to distinguish text fragments that have been mapped to the same internal form.
The usual meaning of indexing is to build a data structure that will allow quick searching of the text, as we mentioned previously. There are many classes of indices, based on different retrieval approaches. For example, we have inverted files (Chapter 3), signature files (Chapter 4), tries (Chapter 5), and so on, as we have seen in the previous section. Almost all type of indices are based on some kind of tree or hashing. Perhaps the main exceptions are clustered data structures (this kind of indexing is called clustering), which is covered in Chapter 16, and the Direct Acyclic Word Graph (DAWG) of the text, which represents all possible subwords of the text using a linear amount of space (Blumer et al. 1985), and is based on finite automata theory.
Usually, before indexing, the text is filtered. Figure 2.7 shows the complete process for the text.
The preprocessing time needed to build the index is amortized by using it in searches. For example, if building the index requires O (n log n) time, we would expect to query the database at least O (n) times to amortize the preprocessing cost. In that case, we add O (log n) preprocessing time to the total query time (that may also be logarithmic).
Many special indices, and their building algorithms (some of them in parallel machines), are covered in this book.
AHO, A., J. HOPCROFT, and J. ULLMAN. 1974. The Design and Analysis of Computer Algorithms. Reading, Mass.: Addison-Wesley.
BAEZA-YATES, R. 1989. "Expected Behaviour of B+-Trees under Random Insertions." Acta Informatica, 26(5), 439-72. Also as Research Report CS-86-67, University of Waterloo, 1986.
BAEZA-YATES, R. 1990. "An Adaptive Overflow Technique for the B-tree," in Extending Data Base Technology Conference (EDBT 90), eds. F. Bancilhon, C. Thanos and D. Tsichritzis, pp. 16-28, Venice. Springer Verlag Lecture Notes in Computer Science 416.
BAEZA-YATES, R., and P.-A. LARSON. 1989. "Performance of B+-trees with Partial Expansions." IEEE Trans. on Knowledge and Data Engineering, 1, 248-57. Also as Research Report CS-87-04, Dept. of Computer Science, University of Waterloo, 1987.
BAYER, R., and E. MCCREIGHT. 1972. "Organization and Maintenance of Large Ordered Indexes."Acta Informatica, 1(3), 173-89.
BAYER, R., and K. UNTERAUER. 1977. "Prefix B-trees." ACM TODS, 2(1), 11-26.
BELL, J., and C. KAMAN. 1970. "The Linear Quotient Hash Code." CACM, 13(11), 675-77.
BLUMER, A., J. BLUMER, D. HAUSSLER, A. EHRENFEUCHT, M. CHEN, and J. SEIFERAS. 1985. "The Smallest Automaton Recognizing the Subwords of a Text." Theoretical Computer Science, 40, 31-55.
DE LA BRIANDAIS, R. 1959. "File Searching Using Variable Length Keys, in AFIPS Western JCC, pp. 295-98, San Francisco, Calif.
DEVROYE, L. 1982. "A Note on the Average Depth of Tries." Computing, 28, 367-71.
FAGIN, R., J. NIEVERGELT, N. PIPPENGER, and H. STRONG. 1979. "Extendible Hashing--a Fast Access Method for Dynamic Files. ACM TODS, 4(3), 315-44.
FALOUTSOS, C. 1987. Signature Files: An Integrated Access Method for Text and Attributes, Suitable for Optical Disk Storage." Technical Report CS-TR-1867, University of Maryland.
FREDKIN, E. 1960. "Trie Memory." CACM, 3, 490-99.
GONNET, G. 1987. "Extracting Information from a Text Database: An Example with Dates and Numerical Data," in Third Annual Conference of the UW Centre for the New Oxford English Dictionary, pp. 85-89, Waterloo, Canada.
GONNET, G. and R. BAEZA-YATES. 1991. Handbook of Algorithms and Data Structures--In Pascal and C. (2nd ed.). Wokingham, U.K.: Addison-Wesley.
GUIBAS, L., and E. SZEMEREDI. 1978. "The Analysis of Double Hashing." JCSS, 16(2), 226-74.
HOPCROFT, J., and J. ULLMAN. 1979. Introduction to Automata Theory. Reading, Mass.: Addison-Wesley.
KNOTT, G. D. 1975. "Hashing Functions." Computer Journal, 18(3), 265-78.
KNUTH, D. 1973. The Art of Computer Programming: Sorting and Searching, vol. 3. Reading, Mass.: Addison-Wesley.
LARSON, P.-A. 1980. "Linear Hashing with Partial Expansions," in VLDB, vol. 6, pp. 224-32, Montreal.
LARSON, P.-A., and A. KAJLA. 1984. "File Organization: Implementation of a Method Guaranteeing Retrieval in One Access." CACM, 27(7), 670-77.
LITWlN, W. 1980. "Linear Hashing: A New Tool for File and Table Addressing," in VLDB, vol. 6, pp. 212-23, Montreal.
LITWIN, W., and LOMET, D. 1987. "A New Method for Fast Data Searches with Keys. IEEE Software, 4(2), 16-24.
LOMET, D. 1987. "Partial Expansions for File Organizations with an Index. ACM TODS, 12: 65-84. Also as tech report, Wang Institute, TR-86-06, 1986.
MCCREIGHT, E. 1976. "A Space-Economical Suffix Tree Construction Algorithm." JACM, 23, 262-72.
MORRlSON, D. 1968. "PATRlClA-Practical Algorithm to Retrieve Information Coded in Alphanumeric." JACM, 15, 514-34.
PETERSON, W. 1957. "Addressing for Random-Access Storage. IBM J Res. Development, 1(4), 130-46.
PITTEL, B. 1986. "Paths in a Random Digital Tree: Limiting Distributions." Adv. Appl. Prob., 18, 139-55.
REGNIER, M. 1981. "On the Average Height of Trees in Digital Search and Dynamic Hashing." Inf. Proc. Letters, 13, 64-66.
ULLMAN, J. 1972. "A Note on the Efficiency of Hashing Functions." JACM, 19(3), 569-75.
WEINER, P. 1973. "Linear Pattern Matching Algorithm," in FOCS, vol. 14, pp. 1-11.
WILLIAMS, F. 1959. "Handling Identifiers as Internal Symbols in Language Processors." CACM, 2(6), 21-24.
YAO, A. 1979. "The Complexity of Pattern Matching for a Random String." SIAM J. Computing, 8, 368-87.
2.2 BASIC CONCEPTS
2.2.1 Strings
 to denote the alphabet (a set of symbols). We say that the alphabet is finite if there exists a bound in the size of the alphabet, denoted by
to denote the alphabet (a set of symbols). We say that the alphabet is finite if there exists a bound in the size of the alphabet, denoted by  . Otherwise, if we do not know a priori a bound in the alphabet size, we say that the alphabet is arbitrary. A string over an alphabet is a finite length sequence of symbols from . The empty string (
. Otherwise, if we do not know a priori a bound in the alphabet size, we say that the alphabet is arbitrary. A string over an alphabet is a finite length sequence of symbols from . The empty string ( ) is the string with no symbols. If x and y are strings, xy denotes the concatenation of x and y. If
) is the string with no symbols. If x and y are strings, xy denotes the concatenation of x and y. If  = xyz is a string, then x is a prefix, and z a suffix of . The length of a string x (x) is the number of symbols of x. Any contiguous sequence of letters y from a string is called a substring. If the letters do not have to be contiguous, we say that y is a subsequence.
= xyz is a string, then x is a prefix, and z a suffix of . The length of a string x (x) is the number of symbols of x. Any contiguous sequence of letters y from a string is called a substring. If the letters do not have to be contiguous, we say that y is a subsequence.2.2.2 Similarity between Strings
d(s1, s1) = 0, d(s1, s2)
 0, d(s1, s3)
0, d(s1, s3)  d(s1, s2) + d(s2, s3)
d(s1, s2) + d(s2, s3) The Hamming distance is defined over strings of the same length. The function d is defined as the number of symbols in the same position that are different (number of mismatches). For example, d(text,that) = 2. The edit distance is defined as the minimal number of symbols that is necessary to insert, delete, or substitute to transform a string s1 to s2. Clearly, d(s1, s2) length(s1) - length(s2). For example, d(text, tax) = 2.
The Hamming distance is defined over strings of the same length. The function d is defined as the number of symbols in the same position that are different (number of mismatches). For example, d(text,that) = 2. The edit distance is defined as the minimal number of symbols that is necessary to insert, delete, or substitute to transform a string s1 to s2. Clearly, d(s1, s2) length(s1) - length(s2). For example, d(text, tax) = 2.2.2.3 Regular Expressions
is a set of strings over . Let L1 and L2 be two languages. The language {xyx L1 and y L2} is called the concatenation of L1 and L2 and is denoted by L1 L2. If L is a language, we define L0 = {} and Li = LLi-1 for i 1. The star or Kleene closure of L, L*, is the language 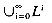 . The plus or positive closure is defined by L+ = LL*. and the languages that they denote (regular sets or regular languages) are defined recursively as follows:
. The plus or positive closure is defined by L+ = LL*. and the languages that they denote (regular sets or regular languages) are defined recursively as follows: 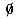 is a regular expression and denotes the empty set. (empty string) is a regular expression and denotes the set {}. For each symbol a in , a is a regular expression and denotes the set {a}. If p and q are regular expressions, then p + q (union), pq (concatenation), and p* (star) are regular expressions that denote L(p)
is a regular expression and denotes the empty set. (empty string) is a regular expression and denotes the set {}. For each symbol a in , a is a regular expression and denotes the set {a}. If p and q are regular expressions, then p + q (union), pq (concatenation), and p* (star) are regular expressions that denote L(p)  L(q), L(p)L(q), and L(p)*, respectively. to denote any symbol from (when the ambiguity is clearly resolvable by context). r? to denote zero or one occurrence of r (that is, r? = + r). [a1 . . am] to denote a range of symbols from . For this we need an order in . rk to denote
L(q), L(p)L(q), and L(p)*, respectively. to denote any symbol from (when the ambiguity is clearly resolvable by context). r? to denote zero or one occurrence of r (that is, r? = + r). [a1 . . am] to denote a range of symbols from . For this we need an order in . rk to denote 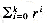 (finite closure).
(finite closure).<A>Scot
80 <W>(Kenilw + Discov)<bl>[a..z]*</bl>
<EQ>(<LQ>)?<Q><D> 161(0+1)</D> <A>Shak
<A>((Sirb)? W)?bScott b?</A>
2.2.4 Finite Automata
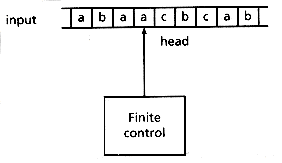
Figure 2.1: A finite automaton
,  , q0, F) (see Hopcroft and Ullman [1979]), where Q is a finite set of states, is a finite input alphabet, q0 Q is the initial state, F
, q0, F) (see Hopcroft and Ullman [1979]), where Q is a finite set of states, is a finite input alphabet, q0 Q is the initial state, F  Q is the set of final states, and is the (partial) transition function mapping Q X ( + {}) to zero or more elements of Q. That is, (q, a) describes the next state(s), for each state q and input symbol a; or is undefined. (q, a), and moves the reading head one position to the right. If (q, a) F, we say that the FA has accepted the string written on its input tape up to the last symbol read. If (q, a) has an unique value for every q and a, we say that the FA is deterministic (DFA); otherwise we say that it is nondeterministic (NFA). transitions (O(|r|2) states) and to a DFA (0(2|r|) states in the worst case). the transition from every state (with the exception of states 2 and 3) to state 1 upon reading a <, and the default transition from all the states to state 0 when there is no transition defined for the read symbol.
Q is the set of final states, and is the (partial) transition function mapping Q X ( + {}) to zero or more elements of Q. That is, (q, a) describes the next state(s), for each state q and input symbol a; or is undefined. (q, a), and moves the reading head one position to the right. If (q, a) F, we say that the FA has accepted the string written on its input tape up to the last symbol read. If (q, a) has an unique value for every q and a, we say that the FA is deterministic (DFA); otherwise we say that it is nondeterministic (NFA). transitions (O(|r|2) states) and to a DFA (0(2|r|) states in the worst case). the transition from every state (with the exception of states 2 and 3) to state 1 upon reading a <, and the default transition from all the states to state 0 when there is no transition defined for the read symbol.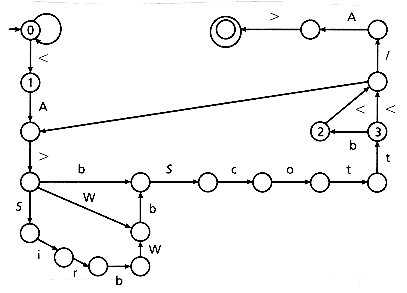
Figure 2.2: DFA example for <A>((Sir b)? W)?bScott b? < / A>.
|n log n) algorithm to minimize a DFA with n states. function is not defined for all possible symbols of for each state. In that case, there is an implicit error state belonging to F for every undefined transition.2.3 DATA STRUCTURES
Search trees: for optical disk files (Chapter 6), prefix B-trees (Chapter 3), stoplists (Chapter 7). Hashing: hashing itself (Chapter 13), string searching (Chapter 10), associated retrieval, Boolean operations (Chapters 12 and 15), optical disk file structures (Chapter 6), signature files (Chapter 4), stoplists (Chapter 7). Digital trees: string searching (Chapter 10), suffix trees (Chapter 5).2.3.1 Search Trees
The root has between 2 and 2m keys, while all other internal nodes have between m and 2m keys. If ki is the i-th key of a given internal node, then all keys in the i - 1 - th child are smaller than ki, while all the keys in the i-th child are bigger. All leaves are at the same depth.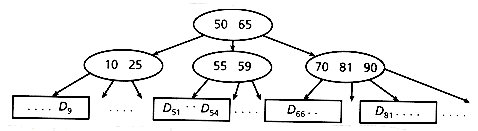
Figure 2.3: A B+ -tree example (Di denotes the primary key i, plus its associated data).
 .69 (Yao 1979; Baeza-Yates 1989). B*-trees: in case of overflow, we first see if neighboring nodes have space. In that case, a subset of the keys is shifted, avoiding a split. With this technique, 66 percent minimal storage utilization is provided. The main disadvantage is that updates are more expensive (Bayer and McCreight 1972; Knuth 1973). Partial expansions: buckets of different sizes are used. If an overflow occurs, a bucket is expanded (if possible), or split. Using two bucket sizes of relative ratio 2/3, 66 percent minimal and 81 percent average storage utilization is achieved (Lomet 1987; Baeza-Yates and Larson 1989). This technique does not deteriorate update time. Adaptive splits: two bucket sizes of relative ratios 1/2 are used. However, splits are not symmetric (balanced), and they depend on the insertion point. This technique achieves 77 percent average storage utilization and is robust against nonuniform distributions (low variance) (Baeza-Yates 1990).
.69 (Yao 1979; Baeza-Yates 1989). B*-trees: in case of overflow, we first see if neighboring nodes have space. In that case, a subset of the keys is shifted, avoiding a split. With this technique, 66 percent minimal storage utilization is provided. The main disadvantage is that updates are more expensive (Bayer and McCreight 1972; Knuth 1973). Partial expansions: buckets of different sizes are used. If an overflow occurs, a bucket is expanded (if possible), or split. Using two bucket sizes of relative ratio 2/3, 66 percent minimal and 81 percent average storage utilization is achieved (Lomet 1987; Baeza-Yates and Larson 1989). This technique does not deteriorate update time. Adaptive splits: two bucket sizes of relative ratios 1/2 are used. However, splits are not symmetric (balanced), and they depend on the insertion point. This technique achieves 77 percent average storage utilization and is robust against nonuniform distributions (low variance) (Baeza-Yates 1990).2.3.2 Hashing

Figure 2.4: Insertion of a new key using double hashing.
2.3.3 Digital Trees
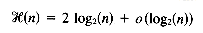
 + O (n) (Knuth 1973).
+ O (n) (Knuth 1973).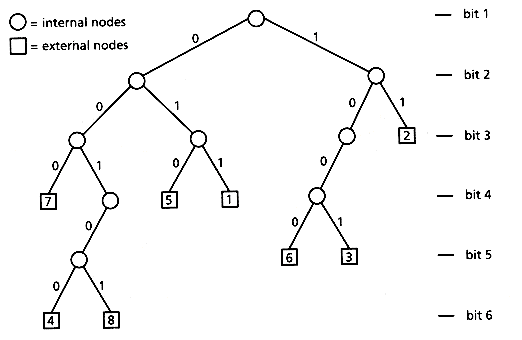
Figure 2.5: Binary trie (external node label indicates position in the text) for the first eight suffixes in "01100100010111 . . .".
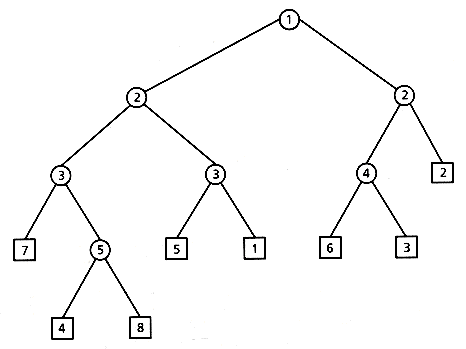
Figure 2.6: Patricia tree (internal node label indicates bit number).
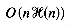 time, where
time, where 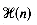 denotes the height of the tree. As for tries, the expected height of a Patricia tree is logarithmic (and at most the height of the binary trie). The expected height of a Patricia tree is log2 n + o(log2 n) (Pittel 1986).
denotes the height of the tree. As for tries, the expected height of a Patricia tree is logarithmic (and at most the height of the binary trie). The expected height of a Patricia tree is log2 n + o(log2 n) (Pittel 1986).2.4 ALGORITHMS
2.4.1 Retrieval Algorithms
Sequential scanning of the text: extra memory is in the worst case a function of the query size, and not of the database size. On the other hand, the running time is at least proportional to the size of the text, for example, string searching (Chapter 10). Indexed text: an "index" of the text is available, and can be used to speed up the search. The index size is usually proportional to the database size, and the search time is sublinear on the size of the text, for example, inverted files (Chapter 3) and signature files (Chapter 4). *q* (q for short) and obtaining some or all of the following information: *q*, find a position m 0 such that t m q*. For example, the first occurrence is defined as the least m that fulfills this condition. is not a member of L(q). If it is, the answer is trivial. Note that string matching is a particular case where q is a string. Algorithms to solve this problem are discussed in Chapter 10.2.4.2 Filtering Algorithms
Common words removed using a list of stopwords. This operation is discussed in Chapter 7. Uppercase letters transformed to lowercase letters. Special symbols removed and sequences of multiple spaces reduced to one space. Numbers and dates transformed to a standard format (Gonnet 1987). Spelling variants transformed using Soundex-like methods (Knuth 1973). Word stemming (removing suffixes and/or prefixes). This is the topic of Chapter 8. Automatic keyword extraction. Word ranking.2.4.3 Indexing Algorithms

Figure 2.7: Text preprocessing
REFERENCES