


Software Engineering Guild, Sterling, VA 22170
Abstract
This chapter introduces and defines basic IR concepts, and presents a domain model of IR systems that describes their similarities and differences. The domain model is used to introduce and relate the chapters that follow. The relationship of IR systems to other information systems is dicussed, as is the evaluation of IR systems.
Automated information retrieval (IR) systems were originally developed to help manage the huge scientific literature that has developed since the 1940s. Many university, corporate, and public libraries now use IR systems to provide access to books, journals, and other documents. Commercial IR systems offer databases containing millions of documents in myriad subject areas. Dictionary and encyclopedia databases are now widely available for PCs. IR has been found useful in such disparate areas as office automation and software engineering. Indeed, any discipline that relies on documents to do its work could potentially use and benefit from IR.
This book is about the data structures and algorithms needed to build IR systems. An IR system matches user queries--formal statements of information needs--to documents stored in a database. A document is a data object, usually textual, though it may also contain other types of data such as photographs, graphs, and so on. Often, the documents themselves are not stored directly in the IR system, but are represented in the system by document surrogates. This chapter, for example, is a document and could be stored in its entirety in an IR database. One might instead, however, choose to create a document surrogate for it consisting of the title, author, and abstract. This is typically done for efficiency, that is, to reduce the size of the database and searching time. Document surrogates are also called documents, and in the rest of the book we will use document to denote both documents and document surrogates.
An IR system must support certain basic operations. There must be a way to enter documents into a database, change the documents, and delete them. There must also be some way to search for documents, and present them to a user. As the following chapters illustrate, IR systems vary greatly in the ways they accomplish these tasks. In the next section, the similarities and differences among IR systems are discussed.
This book contains many data structures, algorithms, and techniques. In order to find, understand, and use them effectively, it is necessary to have a conceptual framework for them. Domain analysis--systems analysis for multiple related systems--described in Prieto-Diaz and Arrango (1991), is a method for developing such a framework. Via domain analysis, one attempts to discover and record the similarities and differences among related systems.
The first steps in domain analysis are to identify important concepts and vocabulary in the domain, define them, and organize them with a faceted classification. Table 1.1 is a faceted classification for IR systems, containing important IR concepts and vocabulary. The first row of the table specifies the facets--that is, the attributes that IR systems share. Facets represent the parts of IR systems that will tend to be constant from system to system. For example, all IR systems must have a database structure--they vary in the database structures they have; some have inverted file structures, some have flat file structures, and so on.
A given IR system can be classified by the facets and facet values, called terms, that it has. For example, the CATALOG system (Frakes 1984) discussed in Chapter 8 can be classified as shown in Table 1.2.
Terms within a facet are not mutually exclusive, and more than one term from a facet can be used for a given system. Some decisions constrain others. If one chooses a Boolean conceptual model, for example, then one must choose a parse method for queries.
Viewed another way, each facet is a design decision point in developing the architecture for an IR system. The system designer must choose, for each facet, from the alternative terms for that facet. We will now discuss the facets and their terms in greater detail.
The most general facet in the previous classification scheme is conceptual model. An IR conceptual model is a general approach to IR systems. Several taxonomies for IR conceptual models have been proposed. Faloutsos (1985) gives three basic approaches: text pattern search, inverted file search, and signature search. Belkin and Croft (1987) categorize IR conceptual models differently. They divide retrieval techniques first into exact match and inexact match. The exact match category contains text pattern search and Boolean search techniques. The inexact match category contains such techniques as probabilistic, vector space, and clustering, among others. The problem with these taxonomies is that the categories are not mutually exclusive, and a single system may contain aspects of many of them.
Almost all of the IR systems fielded today are either Boolean IR systems or text pattern search systems. Text pattern search queries are strings or regular expressions. Text pattern systems are more common for searching small collections, such as personal collections of files. The grep family of tools, described in Earhart (1986), in the UNIX environment is a well-known example of text pattern searchers. Data structures and algorithms for text pattern searching are discussed in Chapter 10.
Almost all of the IR systems for searching large document collections are Boolean systems. In a Boolean IR system, documents are represented by sets of keywords, usually stored in an inverted file. An inverted file is a list of keywords and identifiers of the documents in which they occur. Boolean list operations are discussed in Chapter 12. Boolean queries are keywords connected with Boolean logical operators (AND, OR, NOT). While Boolean systems have been criticized (see Belkin and Croft [1987] for a summary), improving their retrieval effectiveness has been difficult. Some extensions to the Boolean model that may improve IR performance are discussed in Chapter 15.
Researchers have also tried to improve IR performance by using information about the statistical distribution of terms, that is the frequencies with which terms occur in documents, document collections, or subsets of document collections such as documents considered relevant to a query. Term distributions are exploited within the context of some statistical model such as the vector space model, the probabilistic model, or the clustering model. These are discussed in Belkin and Croft (1987). Using these probabilistic models and information about term distributions, it is possible to assign a probability of relevance to each document in a retrieved set allowing retrieved documents to be ranked in order of probable relevance. Ranking is useful because of the large document sets that are often retrieved. Ranking algorithms using the vector space model and the probabilistic model are discussed in Chapter 14. Ranking algorithms that use information about previous searches to modify queries are discussed in Chapter 11 on relevance feedback.
In addition to the ranking algorithms discussed in Chapter 14, it is possible to group (cluster) documents based on the terms that they contain and to retrieve from these groups using a ranking methodology. Methods for clustering documents and retrieving from these clusters are discussed in Chapter 16.
A fundamental decision in the design of IR systems is which type of file structure to use for the underlying document database. As can be seen in Table 1.1, the file structures used in IR systems are flat files, inverted files, signature files, PAT trees, and graphs. Though it is possible to keep file structures in main memory, in practice IR databases are usually stored on disk because of their size.
Using a flat file approach, one or more documents are stored in a file, usually as ASCII or EBCDIC text. Flat file searching (Chapter 10) is usually done via pattern matching. On UNIX, for example, one can store a document collection one per file in a UNIX directory, and search it using pattern searching tools such as grep (Earhart 1986) or awk (Aho, Kernighan, and Weinberger 1988).
An inverted file (Chapter 3) is a kind of indexed file. The structure of an inverted file entry is usually keyword, document-ID, field-ID. A keyword is an indexing term that describes the document, document-ID is a unique identifier for a document, and field-ID is a unique name that indicates from which field in the document the keyword came. Some systems also include information about the paragraph and sentence location where the term occurs. Searching is done by looking up query terms in the inverted file.
Signature files (Chapter 4) contain signatures--it patterns--that represent documents. There are various ways of constructing signatures. Using one common signature method, for example, documents are split into logical blocks each containing a fixed number of distinct significant, that is, non-stoplist (see below), words. Each word in the block is hashed to give a signature--a bit pattern with some of the bits set to 1. The signatures of each word in a block are OR'ed together to create a block signature. The block signatures are then concatenated to produce the document signature. Searching is done by comparing the signatures of queries with document signatures.
PAT trees (Chapter 5) are Patricia trees constructed over all sistrings in a text. If a document collection is viewed as a sequentially numbered array of characters, a sistring is a subsequence of characters from the array starting at a given point and extending an arbitrary distance to the right. A Patricia tree is a digital tree where the individual bits of the keys are used to decide branching.
Graphs, or networks, are ordered collections of nodes connected by arcs. They can be used to represent documents in various ways. For example, a kind of graph called a semantic net can be used to represent the semantic relationships in text often lost in the indexing systems above. Although interesting, graph-based techniques for IR are impractical now because of the amount of manual effort that would be needed to represent a large document collection in this form. Since graph-based approaches are currently impractical, we have not covered them in detail in this book.
Queries are formal statements of information needs put to the IR system by users. The operations on queries are obviously a function of the type of query, and the capabilities of the IR system. One common query operation is parsing (Chapters 3 and 7), that is breaking the query into its constituent elements. Boolean queries, for example, must be parsed into their constituent terms and operators. The set of document identifiers associated with each query term is retrieved, and the sets are then combined according to the Boolean operators (Chapter 12).
In feedback (Chapter 11), information from previous searches is used to modify queries. For example, terms from relevant documents found by a query may be added to the query, and terms from nonrelevant documents deleted. There is some evidence that feedback can significantly improve IR performance.
Operations on terms in an IR system include stemming (Chapter 8), truncation (Chapter 10), weighting (Chapter 14), and stoplist (Chapter 7) and thesaurus (Chapter 9) operations. Stemming is the automated conflation (fusing or combining) of related words, usually by reducing the words to a common root form. Truncation is manual conflation of terms by using wildcard characters in the word, so that the truncated term will match multiple words. For example, a searcher interested in finding documents about truncation might enter the term "truncat?" which would match terms such as truncate, truncated, and truncation. Another way of conflating related terms is with a thesaurus which lists synonymous terms, and sometimes the relationships among them. A stoplist is a list of words considered to have no indexing value, used to eliminate potential indexing terms. Each potential indexing term is checked against the stoplist and eliminated if found there.
In term weighting, indexing or query terms are assigned numerical values usually based on information about the statistical distribution of terms, that is, the frequencies with which terms occur in documents, document collections, or subsets of document collections such as documents considered relevant to a query.
Documents are the primary objects in IR systems and there are many operations for them. In many types of IR systems, documents added to a database must be given unique identifiers, parsed into their constituent fields, and those fields broken into field identifiers and terms. Once in the database, one sometimes wishes to mask off certain fields for searching and display. For example, the searcher may wish to search only the title and abstract fields of documents for a given query, or may wish to see only the title and author of retrieved documents. One may also wish to sort retrieved documents by some field, for example by author. There are many sorting algorithms and because of the generality of the subject we have not covered it in this book. A good description of sorting algorithms in C can be found in Sedgewick (1990). Display operations include printing the documents, and displaying them on a CRT.
Using information about term distributions, it is possible to assign a probability of relevance to each document in a retrieved set, allowing retrieved documents to be ranked in order of probable relevance (Chapter 14). Term distribution information can also be used to cluster similar documents in a document space (Chapter 16).
Another important document operation is display. The user interface of an IR system, as with any other type of information system, is critical to its successful usage. Since user interface algorithms and data structures are not IR specific, we have not covered them in detail here.
Hardware affects the design of IR systems because it determines, in part, the operating speed of an IR system--a crucial factor in interactive information systems--and the amounts and types of information that can be stored practically in an IR system. Most IR systems in use today are implemented on von Neumann machines--general purpose computers with a single processor. Most of the discussion of IR techniques in this book assumes a von Neumann machine as an implementation platform. The computing speeds of these machines have improved enormously over the years, yet there are still IR applications for which they may be too slow. In response to this problem, some researchers have examined alternative hardware for implementing IR systems. There are two approaches--parallel computers and IR specific hardware.
Chapter 18 discusses implementation of an IR system on the Connection machine--a massively parallel computer with 64,000 processors. Chapter 17 discusses IR specific hardware--machines designed specifically to handle IR operations. IR specific hardware has been developed both for text scanning and for common operations like Boolean set combination.
Along with the need for greater speed has come the need for storage media capable of compactly holding the huge document databases that have proliferated. Optical storage technology, capable of holding gigabytes of information on a single disk, has met this need. Chapter 6 discusses data structures and algorithms that allow optical disk technology to be successfully exploited for IR.
Figure 1.1 shows the activities associated with a common type of Boolean IR system, chosen because it represents the operational standard for IR systems.
When building the database, documents are taken one by one, and their text is broken into words. The words from the documents are compared against a stoplist--a list of words thought to have no indexing value. Words from the document not found in the stoplist may next be stemmed. Words may then also be counted, since the frequency of words in documents and in the database as a whole are often used for ranking retrieved documents. Finally, the words and associated information such as the documents, fields within the documents, and counts are put into the database. The database then might consist of pairs of document identifiers and keywords as follows.
Such a structure is called an inverted file. In an IR system, each document must have a unique identifier, and its fields, if field operations are supported, must have unique field names.
To search the database, a user enters a query consisting of a set of keywords connected by Boolean operators (AND, OR, NOT). The query is parsed into its constituent terms and Boolean operators. These terms are then looked up in the inverted file and the list of document identifiers corresponding to them are combined according to the specified Boolean operators. If frequency information has been kept, the retrieved set may be ranked in order of probable relevance. The result of the search is then presented to the user. In some systems, the user makes judgments about the relevance of the retrieved documents, and this information is used to modify the query automatically by adding terms from relevant documents and deleting terms from nonrelevant documents. Systems such as this give remarkably good retrieval performance given their simplicity, but their performance is far from perfect. Many techniques to improve them have been proposed.
One such technique aims to establish a connection between morphologically related terms. Stemming (Chapter 8) is a technique for conflating term variants so that the semantic closeness of words like "engineer," "engineered," and "engineering" will be recognized in searching. Another way to relate terms is via thesauri, or synonym lists, as discussed in Chapter 9.
How do IR systems relate to different types of information systems such as database management systems (DBMS), and artificial intelligence (AI) systems? Table 1.3 summarizes some of the similarities and differences.
One difference between IR, DBMS, and AI systems is the amount of usable structure in their data objects. Documents, being primarily text, in general have less usable structure than the tables of data used by relational DBMS, and structures such as frames and semantic nets used by AI systems. It is possible, of course, to analyze a document manually and store information about its syntax and semantics in a DBMS or an AI system. The barriers for doing this to a large collection of documents are practical rather than theoretical. The work involved in doing knowledge engineering on a set of say 50,000 documents would be enormous. Researchers have devoted much effort to constructing hybrid systems using IR, DBMS, AI, and other techniques; see, for example, Tong (1989). The hope is to eventually develop practical systems that combine IR, DBMS, and AI.
Another distinguishing feature of IR systems is that retrieval is probabilistic. That is, one cannot be certain that a retrieved document will meet the information need of the user. In a typical search in an IR system, some relevant documents will be missed and some nonrelevant documents will be retrieved. This may be contrasted with retrieval from, for example, a DBMS where retrieval is deterministic. In a DBMS, queries consist of attribute-value pairs that either match, or do not match, records in the database.
One feature of IR systems shared with many DBMS is that their databases are often very large--sometimes in the gigabyte range. Book library systems, for example, may contain several million records. Commercial on-line retrieval services such as Dialog and BRS provide databases of many gigabytes. The need to search such large collections in real time places severe demands on the systems used to search them. Selection of the best data structures and algorithms to build such systems is often critical.
Another feature that IR systems share with DBMS is database volatility. A typical large IR application, such as a book library system or commercial document retrieval service, will change constantly as documents are added, changed, and deleted. This constrains the kinds of data structures and algorithms that can be used for IR.
In summary, a typical IR system must meet the following functional and nonfunctional requirements. It must allow a user to add, delete, and change documents in the database. It must provide a way for users to search for documents by entering queries, and examine the retrieved documents. It must accommodate databases in the megabyte to gigabyte range, and retrieve relevant documents in response to queries interactively--often within 1 to 10 seconds.
IR systems can be evaluated in terms of many criteria including execution efficiency, storage efficiency, retrieval effectiveness, and the features they offer a user. The relative importance of these factors must be decided by the designers of the system, and the selection of appropriate data structures and algorithms for implementation will depend on these decisions.
Execution efficiency is measured by the time it takes a system, or part of a system, to perform a computation. This can be measured in C based systems by using profiling tools such as prof (Earhart 1986) on UNIX. Execution efficiency has always been a major concern of IR systems since most of them are interactive, and a long retrieval time will interfere with the usefulness of the system. The nonfunctional requirements of IR systems usually specify maximum acceptable times for searching, and for database maintenance operations such as adding and deleting documents.
Storage efficiency is measured by the number of bytes needed to store data. Space overhead, a common measure of storage efficiency, is the ratio of the size of the index files plus the size of the document files over the size of the document files. Space overhead ratios of from 1.5 to 3 are typical for IR systems based on inverted files.
Most IR experimentation has focused on retrieval effectiveness--usually based on document relevance judgments. This has been a problem since relevance judgments are subjective and unreliable. That is, different judges will assign different relevance values to a document retrieved in response to a given query. The seriousness of the problem is the subject of debate, with many IR researchers arguing that the relevance judgment reliability problem is not sufficient to invalidate the experiments that use relevance judgments. A detailed discussion of the issues involved in IR experimentation can be found in Salton and McGill (1983) and Sparck-Jones (1981).
Many measures of retrieval effectiveness have been proposed. The most commonly used are recall and precision. Recall is the ratio of relevant documents retrieved for a given query over the number of relevant documents for that query in the database. Except for small test collections, this denominator is generally unknown and must be estimated by sampling or some other method. Precision is the ratio of the number of relevant documents retrieved over the total number of documents retrieved. Both recall and precision take on values between 0 and 1.
Since one often wishes to compare IR performance in terms of both recall and precision, methods for evaluating them simultaneously have been developed. One method involves the use of recall-precision graphs--bivariate plots where one axis is recall and the other precision. Figure 1.2 shows an example of such a plot. Recall-precision plots show that recall and precision are inversely related. That is, when precision goes up, recall typically goes down and vice-versa. Such plots can be done for individual queries, or averaged over queries as described in Salton and McGill (1983), and van Rijsbergen (1979).
A combined measure of recall and precision, E, has been developed by van Rijsbergen (1979). The evaluation measure E is defined as:
where P = precision, R = recall, and b is a measure of the relative importance, to a user, of recall and precision. Experimenters choose values of E that they hope will reflect the recall and precision interests of the typical user. For example, b levels of .5, indicating that a user was twice as interested in precision as recall, and 2, indicating that a user was twice as interested in recall as precision, might be used.
IR experiments often use test collections which consist of a document database and a set of queries for the data base for which relevance judgments are available. The number of documents in test collections has tended to be small, typically a few hundred to a few thousand documents. Test collections are available on an optical disk (Fox 1990). Table 1.4 summarizes the test collections on this disk.
IR experiments using such small collections have been criticized as not being realistic. Since real IR databases typically contain much larger collections of documents, the generalizability of experiments using small test collections has been questioned.
This chapter introduced and defined basic IR concepts, and presented a domain model of IR systems that describes their similarities and differences. A typical IR system must meet the following functional and nonfunctional requirements. It must allow a user to add, delete, and change documents in the database. It must provide a way for users to search for documents by entering queries, and examine the retrieved documents. An IR system will typically need to support large databases, some in the megabyte to gigabyte range, and retrieve relevant documents in response to queries interactively--often within 1 to 10 seconds. We have summarized the various approaches, elaborated in subsequent chapters, taken by IR systems in providing these services. Evaluation techniques for IR systems were also briefly surveyed. The next chapter is an introduction to data structures and algorithms.
AHO, A., B. KERNIGHAN, and P. WEINBERGER. 1988. The AWK Programming Language. Reading, Mass.: Addison-Wesley.
BELKIN N. J., and W. B. CROFT. 1987. "Retrieval Techniques," in Annual Review of Information Science and Technology, ed. M. Williams. New York: Elsevier Science Publishers, 109-145.
EARHART, S. 1986. The UNIX Programming Language, vol. 1. New York: Holt, Rinehart, and Winston.
FALOUTSOS, C. 1985. "Access Methods for Text," Computing Surveys, 17(1), 49-74.
FOX, E., ed. 1990. Virginia Disk One, Blacksburg: Virginia Polytechnic Institute and State University.
FRAKES, W. B. 1984. "Term Conflation for Information Retrieval," in Research and Development in Information Retrieval, ed. C. S. van Rijsbergen. Cambridge: Cambridge University Press.
PRIETO-DIAZ, R., and G. ARANGO. 1991. Domain Analysis: Acquisition of Reusable Information for Software Construction. New York: IEEE Press.
SALTON, G., and M. MCGILL 1983. An Introduction to Modern Information Retrieval. New York: McGraw-Hill.
SEDGEWICK, R. 1990. Algorithms in C. Reading, Mass.: Addison-Wesley.
SPARCK-JONES, K. 1981. Information Retrieval Experiment. London: Butterworths.
TONG, R, ed. 1989. Special Issue on Knowledge Based Techniques for Information Retrieval, International Journal of Intelligent Systems, 4(3).
VAN RIJSBERGEN, C. J. 1979. Information Retrieval. London: Butterworths.
1.1 INTRODUCTION
1.2 A DOMAIN ANALYSIS OF IR SYSTEMS
Table 1.1: Faceted Classification of IR Systems (numbers in parentheses indicate chapters)
Conceptual File Query Term Document Hardware
Model Structure Operations Operations Operations
------------------------------------------------------------------------------
Boolean(1) Flat File(10) Feedback(11) Stem(8) Parse(3,7) vonNeumann(1)
Extended Inverted Parse(3,7) Weight(14) Display Parallel(18)
Boolean(15) File(3)
Probabil- Signature(4) Boolean(12) Thesaurus Cluster(16) IR
istic(14) (9) Specific(17)
String Pat Trees(5) Cluster(16) Stoplist(7) Rank(14) Optical
Search(10) Disk(6)
Vector Graphs(1) Truncation Sort(1) Mag. Disk(1)
Space(14) (10)
Hashing(13) Field Mask(1)
Assign IDs(3)
Table 1.2: Facets and Terms for CATALOG IR System
Facets Terms
-----------------------------------------------------------------
File Structure Inverted file
Query Operations Parse, Boolean
Term Operations Stem, Stoplist, Truncation
Hardware von Neumann, Mag. Disk
Document Operations parse, display, sort, field mask, assign IDs
Conceptual Model Boolean
1.2.1 Conceptual Models of IR
1.2.2 File Structures
1.2.3 Query Operations
1.2.4 Term Operations
1.2.5 Document Operations
1.2.6 Hardware for IR
1.2.7 Functional View of Paradigm IR System
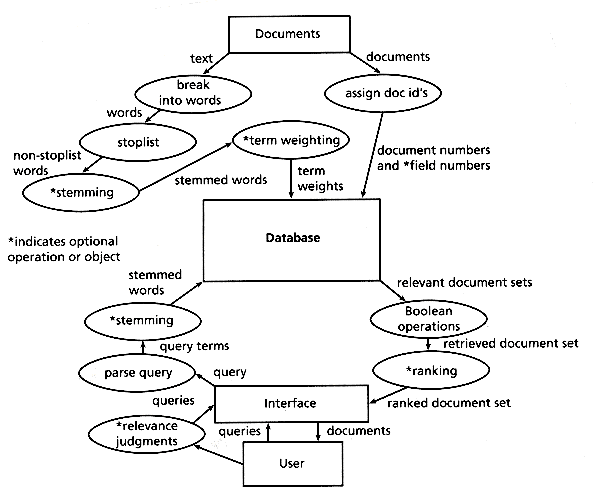
Figure 1.1: Example of Boolean IR system
keyword1 - document1-Field_2
keyword2 - document1-Field_2, 5
keyword2 - document3-Field_1, 2
keyword3 - document3-Field_3, 4

keyword-n - document-n-Field_i, j
1.3 IR AND OTHER TYPES OF INFORMATION SYSTEMS
Table 1.3: IR, DBMS, Al Comparison
Data Object Primary Operation Database Size
------------------------------------------------------------------------
IR document retrieval small to very large
(probabilistic)
DBMS table retrieval small to very large
(relational) (deterministic)
AI logical statements inference usually small
1.4 IR SYSTEM EVALUATION
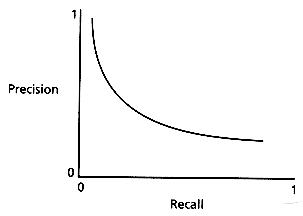
Figure 1.2: Recall-precision graph
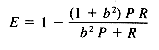
Table 1.4: IR Test Collections
Collection Subject Documents Queries
------------------------------------------------------
ADI Information Science 82 35
CACM Computer Science 3200 64
CISI Library Science 1460 76
CRAN Aeronautics 1400 225
LISA Library Science 6004 35
MED Medicine 1033 30
NLM Medicine 3078 155
NPL Electrical Engineering 11429 100
TIME General Articles 423 83
1.5 SUMMARY
REFERENCES