Searching web pages is one of the most frustrating and problematic tasks performed on the WWW. The situation is getting worse because of
- the Web’s fast growing size (at least 3.98 billion indexed pages as of 01/15/2025) and lack of structural style (semi-structured HTML) and
- the inadequacy of existing web search engine technologies.
- It normally retrieves too many documents, of which only a small fraction are relevant to the users’ needs.
- Furthermore, the most relevant documents do not necessarily appear at the top of the query output list.
On the Internet, a search engine is a coordinated set of programs that traditionally consists of three components:
|
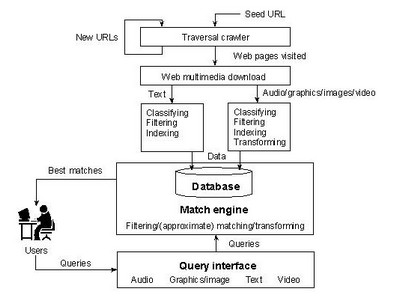
|
- Search and ranking software receives user’s search request, compares it to the entries in the index, and returns results to the user.
|
And God said to John, come forth and you shall be granted eternal life. But John came fifth and won a toaster. |