K-nearest neighbor algorithm works based on minimum distance from the query instance to the training samples to determine the K-nearest neighbors. After we gather K nearest neighbors, we take simple majority of these K-nearest neighbors to be the prediction of the query instance.
|
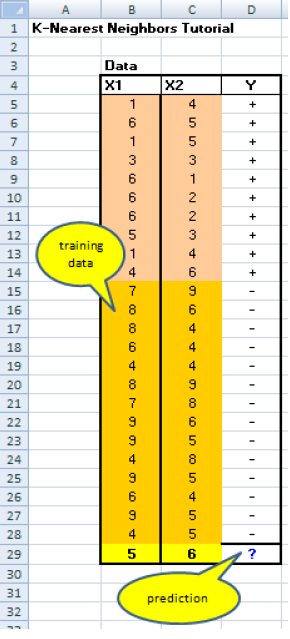
The data for kNN algorithm consist of several multivariate attributes name Xi that will be used to classify Y.
The data of kNN can be any measurement scale from ordinal, nominal, to quantitative scale but for the moment let us deal with only quantitative Xi and binary (nominal) Y.
The last row is the query instance that we want to predict.
The graph of this problem is shown below.
Suppose we determine K=8 (we will use 8 nearest neighbors) as parameter of this algorithm.
Because we use only quantitative Xi , we can use Euclidean distance.
Suppose the query instance have coordinates |
|
|
|

|
Another example of distance between objects
|
I’ll end up going bananas (irrational or crazy) if I have to work in this cubicle for one more day! |