Once you get the information gain for all attributes, then we find the optimal attribute that produces maximum information gain. In our case, travel cost per km produces the maximum information gain. We put this optimal attribute into the node of our decision tree. As it is the first node, then it is the root node of the decision tree. Our decision tree now consists of a single root node. Once we obtain the optimal attribute, we can split the data table according to that optimal attribute.
| In our example, we split the data table based on the value of travel cost per km. |

|
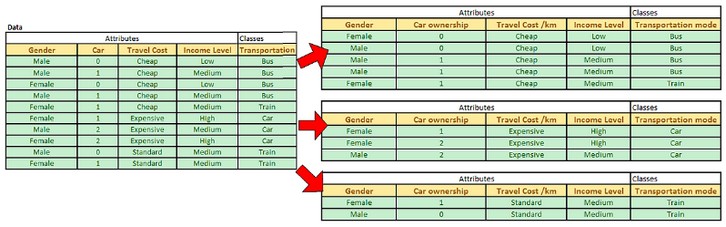
After the split of the data, we can see clearly that value of Expensive travel cost/km is associated only with pure class of Car while Standard travel cost/km is only related to pure class of Train. Pure class is always assigned into leaf node of a decision tree.
| We can use this information to update our decision tree in our first iteration into the tree. |

|
For Cheap travel cost/km, the classes are not pure, thus we need to split further in the next iteration.
|
“There is no escape—we pay for the violence of our ancestors.” ― Frank Herbert, Dune |