The scheme of prediction of taken or not taken requires the calculation of the branch target. This calculation takes one cycle, meaning that taken branches will have a 1-cycle penalty. Theoretically, delayed branches have zero delay, but they include the following disadvantages:
- Branch delay can increase to multiple delay slots in deeper pipelines.
- Branch delay slots must be filled with useful instructions or
nops.
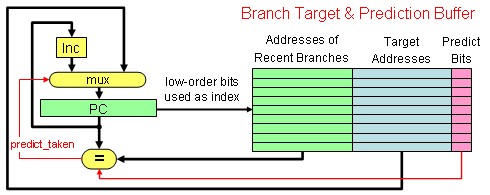
| Branch target buffer is usually organized as a cache with tags, making it more costly than a simple prediction buffer, which uses a small memory instead. |
|
The approach of using a branch target buffer works as follows:
- Check the PC to see if the instruction being fetched is a branch.
- Store the branch target address in a branch buffer in the IF stage.
- If branch is predicted taken,
then “next PC = branch target fetched from branch target buffer”
else “next PC = PC + 4”
| Give me a beer. I am having one for the road (a final drink before leaving). |