Loading a Simple Prefix B+ Tree
Building a simple prefix B+ tree through a series of successive insertions is not feasible because splitting and redistribution blocks are relatively expensive.
Instead, the following steps are used to load a tree:
- Sort the records that are to be loaded.
- Working from a sorted file, place the records into sequence set blocks, one by one, starting a new block when one is filled up.
- During the transition between two sequence set blocks, determine the shortest separator for the blocks.
Collect these separators into an index set block until it is full.
The following example shows how to develop an example of a book index:
- At first, four sequence set blocks have been written out to the disk and one index set block that has been built in memory from the shortest separators derived from the sequence set block keys.
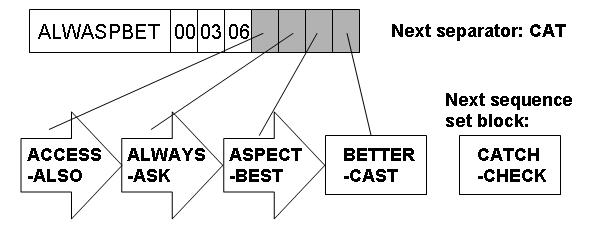
- The next sequence set block consists of a set of terms ranging from CATCH through CHECK, and therefore the next separator is CAT.
Assume the index set block is now full.
The addition of the CAT separator requires us to start a new, root-level index block as well as a lower-level index block.
The resulting tree shown in the following slide would contain an index set node that holds no separators, which violates the B-tree that apply to the index set.