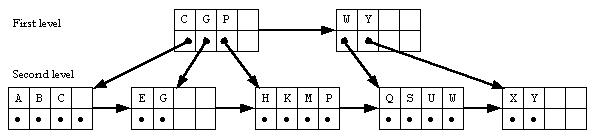
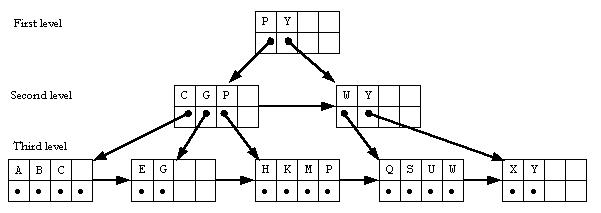
The records are sorted, so the largest key in each index record can be used to represent the entire index record. The key for the records will be C for the first record, G for the second record, and so on. The process can be taken one step further by adding a third level, resulting in the tree below.
The root node is an index record whose references are to nodes at the second level. These second-level nodes are index records whose references are to nodes at the third level. Finally, the third-level nodes are index records whose references are to records in the data file. Cost associated with a multilevel index file includes:
Space overhead: For example, the space overhead is just 1% more for 80000 index records. Certainly this is not a burden.
Search time: For example, an 80-megabyte file can be read with just four disk accesses. This is what we need to produce efficient indexed access!
Insertion and deletion: For example, it may require 80000 reads and writes to insert a new key into 80000 index records. This is truly a fatal flaw in simple multilevel indexing.