An undirected graph G = (V, E) consists of a finite set of vertices V and a set of edges E. It differs from a directed graph in that each edge in E is an unordered pair of vertices.† If (v, w) is an undirected edge, then (v, w) = (w, v). Hereafter we refer to an undirected graph as simply a graph.
Graphs are used in many different disciplines to model a symmetric relationship between objects. The objects are represented by the vertices of the graph and two objects are connected by an edge if the objects are related. In this chapter we present several data structures that can be used to represent graphs. We then present algorithms for three typical problems involving undirected graphs: constructing minimal spanning trees, biconnected components, and maximal matchings.
Much of the terminology for directed graphs is also applicable to undirected graphs. For example, vertices v and w are adjacent if (v, w) is an edge [or, equivalently, if (w, v) is an edge]. We say the edge (v, w) is incident upon vertices v and w.
A path is a sequence of vertices v1, v2, . . . , vn such that (vi, vi+1) is an edge for 1 ú i < n. A path is simple if all vertices on the path are distinct, with the exception that v1 and vn may be the same. The length of the path is n-1, the number of edges along the path. We say the path v1, v2, . . . , vn connects v1 and vn. A graph is connected if every pair of its vertices is connected.
Let G = (V, E) be a graph with vertex set V and edge set E. A subgraph of G is a graph G' = (V', E') where
If E' consists of all edges (v, w) in E, such that both v and w are in V', then G' is called an induced subgraph of G.
Example 7.1. In Fig. 7.1(a) we see a graph G = (V, E) with V = {a, b, c, d} and E = {(a, b), (a, d), (b, c), (b, d), (c, d)}. In Fig. 7.1(b) we see one of its induced subgraphs, the one defined by the set of vertices {a, b, c} and all the edges in Fig. 7.1(a) that are not incident upon vertex d.
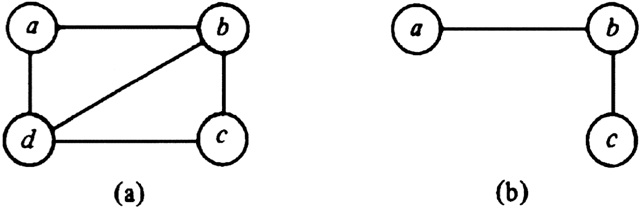
Fig. 7.1. A graph and one of its subgraphs.
A connected component of a graph G is a maximal connected induced subgraph, that is, a connected induced subgraph that is not itself a proper subgraph of any other connected subgraph of G.
Example 7.2 Figure 7.1 is a connected graph. It has only one connected component, namely itself. Figure 7.2 is a graph with two connected components.
Fig. 7.2. An unconnected graph.
A (simple) cycle in a graph is a (simple) path of length three or more that connects a vertex to itself. We do not consider paths of the form v (path of length 0), v, v (path of length 1), or v, w, v (path of length 2) to be cycles. A graph is cyclic if it contains at least one cycle. A connected, acyclic graph is sometimes called a free tree. Figure 7.2 shows a graph consisting of two connected components where each connected component is a free tree. A free tree can be made into an ordinary tree if we pick any vertex we wish as the root and orient each edge from the root.
Free trees have two important properties, which we shall use in the next section.
We can prove (1) by induction on n, or what is equivalent, by an argument concerning the "smallest counterexample." Suppose G = (V, E) is a counterexample to (1) with the fewest vertices, say n vertices. Now n cannot be 1, because the only free tree on one vertex has zero edges, and (1) is satisfied. Therefore, n must be greater than 1.
We now claim that in the free tree there must be some vertex with exactly one incident edge. In proof, no vertex can have zero incident edges, or G would not be connected. Suppose every vertex has at least two edges incident. Then, start at some vertex v1, and follow any edge from v1. At each step, leave a vertex by a different edge from the one used to enter it, thereby forming a path v1, v2, v3, . . ..
Since there are only a finite number of vertices in V, all vertices on this path cannot be distinct; eventually, we find vi = vj for some i < j. We cannot have i = j-1 because there are no loops from a vertex to itself, and we cannot have i = j-2 or else we entered and left vertex vi+1 on the same edge. Thus, i ú j-3, and we have a cycle vi, vi+1, . . . , vj = vi. Thus, we have contradicted the hypothesis that G had no vertex with only one edge incident, and therefore conclude that such a vertex v with edge (v, w) exists.
Now consider the graph G' formed by deleting vertex v and edge (v, w) from G. G' cannot contradict (1), because if it did, it would be a smaller counterexample than G. Therefore, G' has n-1 vertices and n-2 edges. But G has one more edge and one more vertex than G', so G has n-1 edges, proving that G does indeed satisfy (1). Since there is no smallest counterexample to (1), we conclude there can be no counterexample at all, so (1) is true.
Now we can easily prove statement (2), that adding an edge to a free tree forms a cycle. If not, the result of adding the edge to a free tree of n vertices would be a graph with n vertices and n edges. This graph would still be connected, and we supposed that adding the edge left the graph acyclic. Thus we would have a free tree whose vertex and edge count did not satisfy condition (1).
The methods of representing directed graphs can be used to represent undirected graphs. One simply represents an undirected edge between v and w by two directed edges, one from v to w and the other from w to v.
Example 7.3. The adjacency matrix and adjacency list representations for the graph of Fig. 7.1(a) are shown in Fig. 7.3.
Clearly, the adjacency matrix for a graph is symmetric. In the adjacency list representation if (i, j) is an edge, then vertex j is on the list for vertex i and vertex i is on the list for vertex j.
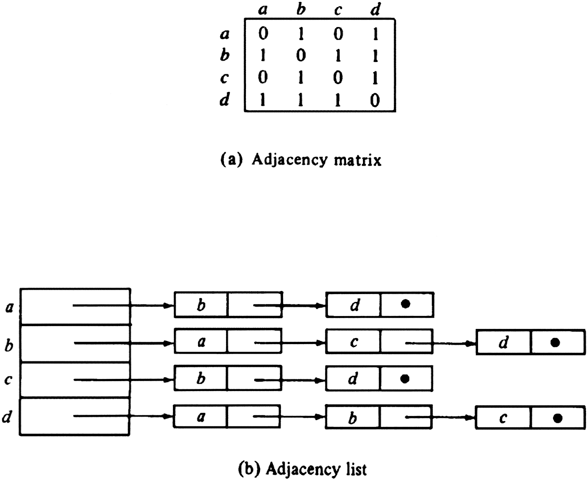
Fig. 7.3. Representations.
Suppose G = (V, E) is a connected graph in which each edge (u, v) in E has a cost c(u, v) attached to it. A spanning tree for G is a free tree that connects all the vertices in V. The cost of a spanning tree is the sum of the costs of the edges in the tree. In this section we shall show how to find a minimum-cost spanning tree for G.
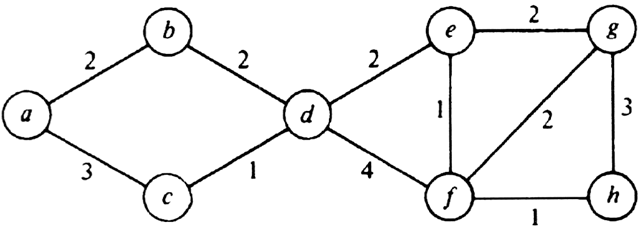
Example 7.4. Figure 7.4 shows a weighted graph and its minimum-cost spanning tree.
A typical application for minimum-cost spanning trees occurs in the design of communications networks. The vertices of a graph represent cities and the edges possible communications links between the cities. The cost associated with an edge represents the cost of selecting that link for the network. A minimum-cost spanning tree represents a communications network that connects all the cities at minimal cost.
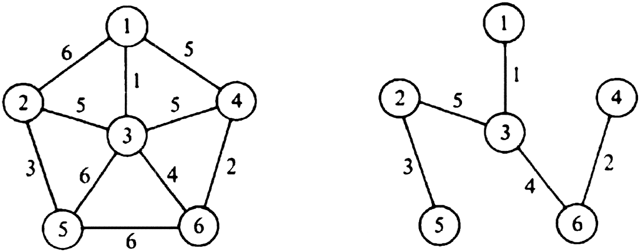
Fig. 7.4. A graph and spanning tree.
There are several different ways to construct a minimum-cost spanning tree. Many of these methods use the following property of minimum-cost spanning trees, which we call the MST property. Let G = (V, E) be a connected graph with a cost function defined on the edges. Let U be some proper subset of the set of vertices V. If (u, v) is an edge of lowest cost such that u ╬ U and v ╬ V-U, then there is a minimum-cost spanning tree that includes (u, v) as an edge.
The proof that every minimum-cost spanning tree satisfies the MST property is not hard. Suppose to the contrary that there is no minimum-cost spanning tree for G that includes (u, v). Let T be any minimum-cost spanning tree for G. Adding (u, v) to T must introduce a cycle, since T is a free tree and therefore satisfies property (2) for free trees. This cycle involves edge (u, v). Thus, there must be another edge (u', v') in T such that u' ╬ U and v' ╬ V-U, as illustrated in Fig. 7.5. If not, there would be no way for the cycle to get from u to v without following the edge (u, v) a second time.
Deleting the edge (u', v') breaks the cycle and yields a spanning tree T' whose cost is certainly no higher than the cost of T since by assumption c(u, v) ú c(u', v'). Thus, T' contradicts our assumption that there is no minimum-cost spanning tree that includes (u, v).
There are two popular techniques that exploit the MST property to construct a minimum-cost spanning tree from a weighted graph G = (V, E). One such method is known as Prim's algorithm. Suppose V = {1, 2, . . . , n}. Prim's algorithm begins with a set U initialized to {1}. It then "grows" a spanning tree, one edge at a time. At each step, it finds a shortest edge (u, v) that connects U and V-U and then adds v, the vertex in V-U, to U. It repeats this
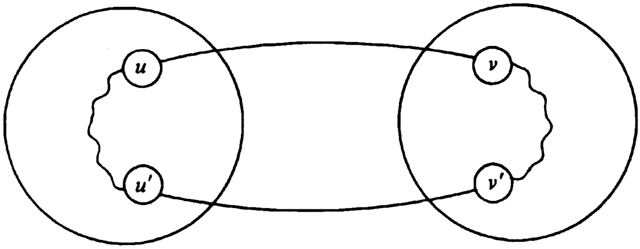
Fig. 7.5. Resulting cycle.
step until U = V. The algorithm is summarized in Fig. 7.6 and the sequence of edges added to T for the graph of Fig. 7.4(a) is shown in Fig. 7.7.
procedure Prim ( G: graph; var T: set of edges );
{ Prim constructs a minimum-cost spanning tree T for G }
var
U: set of vertices;
u, v: vertex;
begin
T:= Ø;
U := {1};
while U ╣ V do begin
let (u, v) be a lowest cost edge such that
u is in U and v is in V-U;
T := T ╚ {(u, v)};
U := U ╚ {v}
end
end; { Prim }
Fig. 7.6. Sketch of Prim's algorithm.
One simple way to find the lowest-cost edge between U and V-U at each step is to maintain two arrays. One array CLOSEST[i] gives the vertex in U that is currently closest to vertex i in V-U. The other array LOWCOST[i] gives the cost of the edge (i, CLOSEST[i]).
At each step we can scan LOWCOST to find the vertex, say k, in V-U that is closest to U. We print the edge (k, CLOSEST[k]). We then update the LOWCOST and CLOSEST arrays, taking into account the fact that k has been
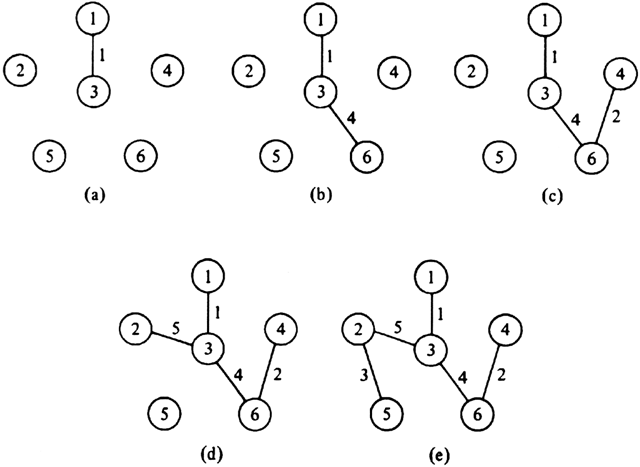
Fig. 7.7. Seqeunces of edges added by Prim's algorithm.
added to U. A Pascal version of this algorithm is given in Fig. 7.8. We assume C is an n x n array such that C[i, j] is the cost of edge (i, j). If edge (i, j) does not exist, we assume C[i, j] is some appropriate large value.
Whenever we find another vertex k for the spanning tree, we make LOWCOST[k] be infinity, a very large value, so this vertex will no longer be considered in subsequent passes for inclusion in U. The value infinity is greater than the cost of any edge or the cost associated with a missing edge.
The time complexity of Prim's algorithm is O(n2), since we make n-1 iterations of the loop of lines (4)-(16) and each iteration of the loop takes O(n) time, due to the inner loops of lines (7)-(10) and (13)-(16). As n gets large the performance of this algorithm may become unsatisfactory. We now give another algorithm due to Kruskal for finding minimum-cost spanning trees whose performance is at most O(eloge), where e is the number of edges in the given graph. If e is much less than n2, Kruskal's algorithm is superior, although if e is about n2, we would prefer Prim's algorithm.
procedure Prim ( C: array[l..n, 1..n] of
real );
{ Prim prints the edges of a minimum-cost spanning tree for a graph
with vertices {1, 2, . . . , n} and cost matrix C on edges }
var
LOWCOST: array[1..n] of real;
CLOSEST: array[1..n] of integer;
i, j, k, min; integer;
{ i and j are indices. During a scan of the LOWCOST array,
k is the index of the closest vertex found so far, and
min = LOWCOST[k] }
begin
(1) for i := 2 to n do begin
{ initialize with only vertex 1 in the set U }
(2) LOWCOST[i] := C[1, i];
(3) CLOSEST[i] := 1
end;
(4) for i := 2 to n do begin
{ find the closest vertex k outside of U to
some vertex in U }
(5) min := LOWCOST[2];
(6) k := 2;
(7) for j := 3 to n do
(8) if LOWCOST[j] < min then begin
(9) min := LOWCOST[j];
(10) k := j
end;
(11) writeln(k, CLOSEST[k]); { print edge }
(12) LOWCOST[k] := infinity; { k is added to U }
(13) for j := 2 to n do { adjust costs to U }
(14) if (C[k, j] < LOWCOST[j]) and
(LOWCOST[j] < infinity) then begin
(15) LOWCOST[j] := C[k, j];
(16) CLOSEST[j] := k
end
end
end; { Prim }
Fig. 7.8. Prim's algorithm.
Suppose again we are given a connected graph G = (V, E), with V = {1, 2, . . . , n} and a cost function c defined on the edges of E. Another way to construct a minimum-cost spanning tree for G is to start with a graph T = (V, Ø) consisting only of the n vertices of G and having no edges. Each vertex is therefore in a connected component by itself. As the algorithm proceeds, we shall always have a collection of connected components, and for each component we shall have selected edges that form a spanning tree.
To build progressively larger components, we examine edges from E, in order of increasing cost. If the edge connects two vertices in two different connected components, then we add the edge to T. If the edge connects two vertices in the same component, then we discard the edge, since it would cause a cycle if we added it to the spanning tree for that connected component. When all vertices are in one component, T is a minimum-cost spanning tree for G.
Example 7.5. Consider the weighted graph of Fig. 7.4(a). The sequence of edges added to T is shown in Fig. 7.9. The edges of cost 1, 2, 3, and 4 are considered first, and all are accepted, since none of them causes a cycle. The edges (1, 4) and (3, 4) of cost 5 cannot be accepted, because they connect vertices in the same component in Fig. 7.9(d), and therefore would complete a cycle. However, the remaining edge of cost 5, namely (2, 3), does not create a cycle. Once it is accepted, we are done.
We can implement this algorithm using sets and set operations discussed in Chapters 4 and 5. First, we need a set consisting of the edges in E. We then apply the DELETEMIN operator repeatedly to this set to select edges in order of increasing cost. The set of edges therefore forms a priority queue, and a partially ordered tree is an appropriate data structure to use here.
We also need to maintain a set of connected components C. The operations we apply to it are:
These are the operations of the MERGE-FIND ADT called MFSET, which we encountered in Section 5.5. A sketch of a program called Kruskal to find a minimum-cost spanning tree using these operations is shown in Fig. 7.10.
We can use the techniques of Section 5.5 to implement the operations used in this program. The running time of this program is dependent on two factors. If there are e edges, it takes O(eloge) time to insert the edges into the priority queue.‡ In each iteration of the while-loop, finding the least cost
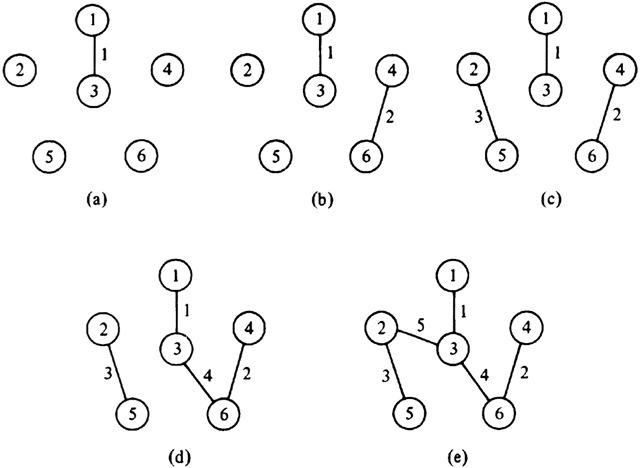
Fig. 7.9. Sequence of edges added by Kruskal's algorithm.
edge in edges takes O(log e) time. Thus, the priority queue operations take O(e log e) time in the worst case. The total time required to perform the MERGE and FIND operations depends on the method used to implement the MFSET. As shown in Section 5.5, there are O(e log e) and O(e a (e)) methods. In either case, Kruskal's algorithm can be implemented to run in O(e log e) time.
In a number of graph problems, we need to visit the vertices of a graph systematically. Depth-first search and breadth-first search, the subjects of this section, are two important techniques for doing this. Both techniques can be used to determine efficiently all vertices that are connected to a given vertex.
procedure Kruskal ( V: SET of vertex;
E: SET of edges;
var T: SET of edges );
var
ncomp: integer; { current number of components }
edges: PRIORITYQUEUE; { the set of edges }
components: MFSET; { the set V grouped into
a MERGE-FIND set of components }
u, v: vertex;
e: edge;
nextcomp: integer; { name for new component }
ucomp, vcomp: integer; { component names }
begin
MAKENULL(T);
MAKENULL(edges);
nextcomp := 0;
ncomp := number of members of V;
for v in V do begin { initialize a
component to contain one vertex of V }
nextcomp := nextcomp + 1;
INITIAL( nextcomp, v, components)
end;
for e in E do { initialize priority queue of edges }
INSERT(e, edges);
while ncomp > 1 do begin { consider next edge }
e := DELETEMIN(edges);
let e = (u, v);
ucomp := FIND(u, components);
vcomp := FIND(v, components);
if ucomp <> vcomp then begin
{ e connects two different components }
MERGE (ucomp, vcomp, components);
ncomp := ncomp - 1;
INSERT(e, T)
end
end
end; { Kruskal }
Fig. 7.10. Kruskal's algorithm.
Recall from Section 6.5 the algorithm dfs for searching a directed graph. The same algorithm can be used to search undirected graphs, since the undirected edge (v, w) may be thought of as the pair of directed edges v « w and w « v.
In fact, the depth-first spanning forests constructed for undirected graphs are even simpler than for digraphs. We should first note that each tree in the forest is one connected component of the graph, so if a graph is connected, it has only one tree in its depth-first spanning forest. Second, for digraphs we identified four kinds of arcs: tree, forward, back, and cross. For undirected graphs there are only two kinds: tree edges and back edges.
Because there is no distinction between forward edges and backward edges for undirected graphs, we elect to refer to them all as back edges. In an undirected graph, there can be no cross edges, that is, edges (v, w) where v is neither an ancestor nor descendant of w in the spanning tree. Suppose there were. Then let v be a vertex that is reached before w in the search. The call to dfs(v) cannot end until w has been searched, so w is entered into the tree as some descendant of v. Similarly, if dfs(w) is called before dfs(v), then v becomes a descendant of w.
As a result, during a depth-first search of an undirected graph G, all edges become either
Example 7.6. Consider the connected graph G in Fig. 7.11(a). A depth-first spanning tree T resulting from a depth-first search of G is shown in Fig. 7.11(b). We assume the search began at vertex a, and we have adopted the convention of showing tree edges solid and back edges dashed. The tree has been drawn with the root on the top and the children of each vertex have been drawn in the left-to-right order in which they were first visited in the procedure of dfs.
To follow a few steps of the search, the procedure dfs(a) calls dfs(b) and adds edge (a, b) to T since b is not yet visited. At b, dfs calls dfs(d) and adds edge (b, d) to T. At d, dfs calls dfs(e) and adds edge (d, e) to T. At e, vertices a, b, and d are marked visited so dfs(e) returns without adding any edges to T. At d, dfs now sees that vertices a and b are marked visited so dfs(d) returns without adding any more edges to T. At b, dfs now sees that the remaining adjacent vertices a and e are marked visited, so dfs(b) returns. The search then continues to c, f, and g.
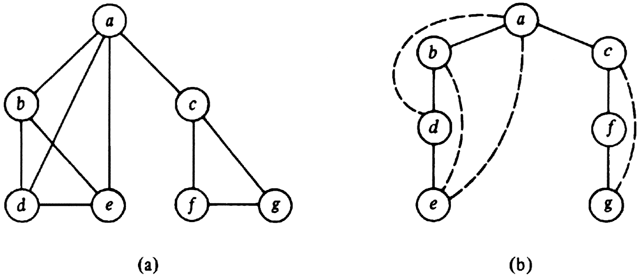
Fig. 7.11. A graph and its depth-first search.
Another systematic way of visiting the vertices is called breadth-first search. The approach is called "breadth-first" because from each vertex v that we visit we search as broadly as possible by next visiting all the vertices adjacent to v. We can also apply this strategy of search to directed graphs.
As for depth-first search, we can build a spanning forest when we perform a breadth-first search. In this case, we consider edge (x, y) a tree edge if vertex y is first visited from vertex x in the inner loop of the search procedure bfs of Fig. 7.12.
It turns out that for the breadth-first search of an undirected graph, every edge that is not a tree edge is a cross edge, that is, it connects two vertices neither of which is an ancestor of the other.
The breadth-first search algorithm given in Fig. 7.12 inserts the tree edges into a set T, which we assume is initially empty. Every entry in the array mark is assumed to be initialized to the value unvisited; Figure 7.12 works on one connected component. If the graph is not connected, bfs must be called on a vertex of each component. Note that in a breadth-first search we must mark a vertex visited before enqueuing it, to avoid placing it on the queue more than once.
Example 7.7. The breadth-first spanning tree for the graph G in Fig. 7.11(a) is shown in Fig. 7.13. We assume the search began at vertex a. As before, we have shown tree edges solid and other edges dashed. We have also drawn the tree with the root at the top and the children in the left-to-right order in which they were first visited.
The time complexity of breadth-first search is the same as that of depth-
procedure bfs ( v );
{ bfs visits all vertices connected to v using breadth-first search }
var
Q: QUEUE of vertex;
x, y: vertex;
begin
mark[v] := visited;
ENQUEUE(v, Q);
while not EMPTY(Q) do begin
x := FRONT(Q);
DEQUEUE(Q);
for each vertex y adjacent to x do
if mark[y] = unvisited then begin
mark[y] := visited;
ENQUEUE(y, Q);
INSERT((x, y), T)
end
end
end; { bfs }
Fig. 7.12. Breadth-first search.
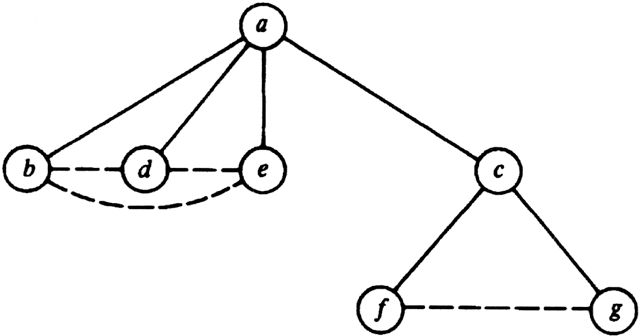
Fig. 7.13. Breadth-first search of G.
first search. Each vertex visited is placed in the queue once, so the body of the while loop is executed once for each vertex. Each edge (x, y) is examined twice, once from x and once from y. Thus, if a graph has n vertices and e edges, the running time of bfs is O(max(n, e)) if we use an adjacency list representation for the edges. Since e │ n is typical, we shall usually refer to the running time of breadth-first search as O(e), just as we did for depth-first search.
Depth-first search and breadth-first search can be used as frameworks around which to design efficient graph algorithms. For example, either method can be used to find the connected components of a graph, since the connected components are the trees of either spanning forest.
We can test for cycles using breadth-first search in O(n) time, where n is the number of vertices, independent of the number of edges. As we discussed in Section 7.1, any graph with n vertices and n or more edges must have a cycle. However, a graph could have n-1 or fewer edges and still have a cycle, if it had two or more connected components. One sure way to find the cycles is to build a breadth-first spanning forest. Then, every cross edge (v, w) must complete a simple cycle with the tree edges leading to v and w from their closest common ancestor, as shown in Fig. 7.14.
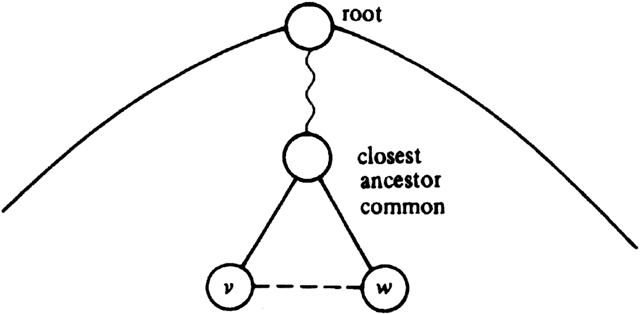
Fig. 7.14 A cycle found by breadth-first search.
An articulation point of a graph is a vertex v such that when we remove v and all edges incident upon v, we break a connected component of the graph into two or more pieces. For example, the articulation points of Fig. 7.11(a) are a and c. If we delete a, the graph, which is one connected component, is divided into two triangles: {b, d, e} and {c, f, g}. If we delete c, we divide the graph into {a, b, d, e} and {f, g}. However, if we delete any one of the other vertices from the graph of Fig. 7.11(a), we do not split the connected component. A connected graph with no articulation points is said to be biconnected. Depth-first search is particularly useful in finding the biconnected components of a graph.
The problem of finding articulation points is the simplest of many important problems concerning the connectivity of graphs. As an example of applications of connectivity algorithms, we may represent a communication network as a graph in which the vertices are sites to be kept in communication with one another. A graph has connectivity k if the deletion of any k-1 vertices fails to disconnect the graph. For example, a graph has connectivity two or more if and only if it has no articulation points, that is, if and only if it is biconnected. The higher the connectivity of a graph, the more likely the graph is to survive the failure of some of its vertices, whether by failure of the processing units at the vertices or external attack.
We shall here give a simple depth-first search algorithm to find all the articulation points of a connected graph, and thereby test by their absence whether the graph is biconnected.
- dfnumber [v],
- dfnumber [z] for any vertex z for which there is a back edge (v, z) and
- low [y] for any child y of v.
- The root is an articulation point if and only if it has two or more children. Since there are no cross edges, deletion of the root must disconnect the subtrees rooted at its children, as a disconnects {b, d, e} from {c, f, g} in Fig. 7.11(b).
- A vertex v other than the root is an articulation point if and only if there is some child w of v such that low [w] │ dfnumber [v]. In this case, v disconnects w and its descendants from the rest of the graph. Conversely, if low [w] < dfnumber [v], then there must be a way to get from w down the tree and back to a proper ancestor of v (the vertex whose dfnumber is low [w]), and therefore deletion of v does not disconnect w or its descendants from the rest of the graph.
Example 7.8. dfnumber and low are computed for the graph of Fig. 7.11(a) in Fig. 7.15. As an example of the calculation of low, our postorder traversal visits e first. At e, there are back edges (e, a) and (e, b), so low [e] is set to min(dfnumber [e], dfnumber [a], dfnumber [b]) = 1. Then d is visited, and low [d] is set to the minimum of dfnumber [d], low [e], and dfnumber [a ]. The second of these arises because e is a child of d and the third because of the back edge (d, a).
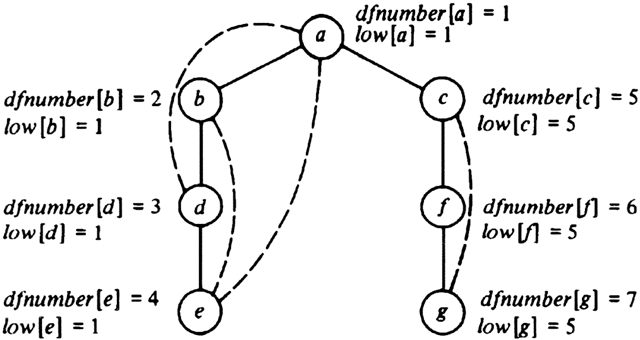
Fig. 7.15. Depth-first and low numberings.
After computing low we consider each vertex. The root, a, is an articulation point because it has two children. Vertex c is an articulation point because it has a child f with low [f] │ dfnumber [c]. The other vertices are not articulation points.
The time taken by the above algorithm on a graph of e edges and n ú e vertices is O(e). The reader should check that the time spent in each of the three phases can be attributed either to the vertex visited or to an edge emanating from that vertex, there being only a constant amount of time attributable to any vertex or edge in any pass. Thus, the total time is O(n+e), which is O(e) under the assumption n ú e.
In this section we outline an algorithm to solve "matching problems" on graphs. A simple example of a matching problem occurs when we have a set of teachers to assign to a set of courses. Each teacher is qualified to teach certain courses but not others. We wish to assign a course to a qualified teacher so that no two teachers are assigned the same course. With certain distributions of teachers and courses it is impossible to assign every teacher a course; in those situations we wish to assign as many teachers as possible.
We can represent this situation by a graph as in Fig. 7.16 where the vertices are divided into two sets V1 and V2, such that vertices in the set V1 represent teachers and vertices in the set V2 courses. That teacher v is qualified to teach course w is represented by an edge (v, w). A graph such as this whose vertices can be divided into two disjoint groups with each edge having one end in each group is called bipartite. Assigning a teacher a course is equivalent to selecting an edge between a teacher vertex and a course vertex.
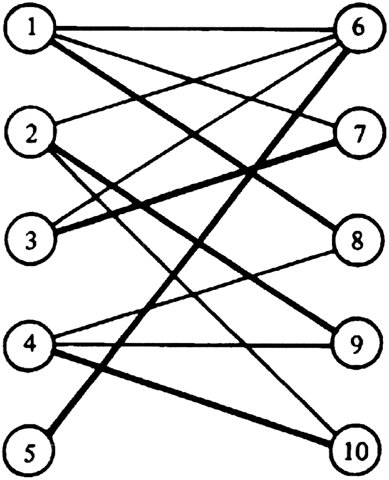
Fig. 7.16. A bipartite graph.
The matching problem can be formulated in general terms as follows. Given a graph G =(V, E), a subset of the edges in E with no two edges incident upon the same vertex in V is called a matching. The task of selecting a maximum subset of such edges is called the maximal matching problem. The heavy edges in Fig. 7.16 are an example of one maximal matching in that graph. A complete matching is a matching in which every vertex is an endpoint of some edge in the matching. Clearly, every complete matching is a maximal matching.
There is a straightforward way to find maximal matchings. We can systematically generate all matchings and then pick one that has the largest number of edges. The difficulty with this method is that it has a running time that is an exponential function of the number of edges.
There are more efficient algorithms for finding maximal matchings. These algorithms generally use a technique known as "augmenting paths." Let M be a matching in a graph G. A vertex v is matched if it is the endpoint of an edge in M. A path connecting two unmatched vertices in which alternate edges in the path are in M is called an augmenting path relative to M. Observe that an augmenting path must be of odd length, and must begin and end with edges not in M. Also observe that given an augmenting path P we can always find a bigger matching by removing from M those edges that are in P, and then adding to M the edges of P that were initially not in M. This new matching is M ┼ P where ┼ denotes "exclusive or" on sets. That is, the new matching consists of those edges that are in M or P, but not in both.
Example 7.9. Figure 7.17(a) shows a graph and a matching M consisting of the heavy edges (1, 6), (3, 7), and (4, 8). The path 2, 6, 1, 8, 4, 9 in Fig. 7.17(b) is an augmenting path relative to M. Figure 7.18 shows the matching (l, 8), (2, 6), (3, 7), (4, 9) obtained by removing from M those edges that are in the path, and then adding to M the other edges in the path.
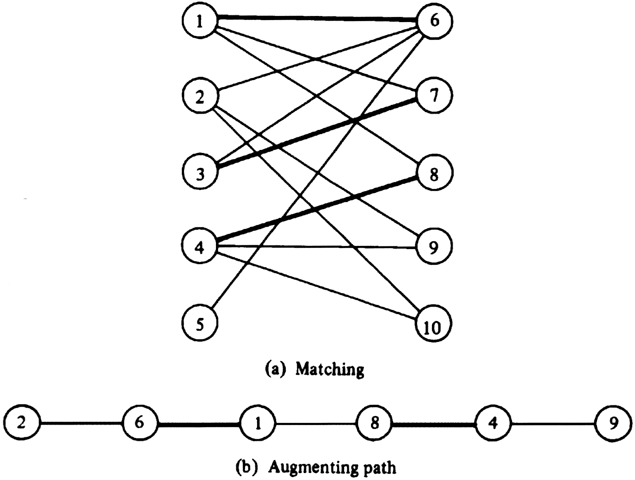
Fig. 7.17. A matching and an augmenting path.
The key observation is that M is a maximal matching if and only if there is no augmenting path relative to M. This observation is the basis of our maximal matching algorithm.
Suppose M and N are matchings with ¢M¢ < ¢N¢. (¢M¢ denotes the number of edges in M.) To see that M ┼ N contains an augmenting path relative to M consider the graph G' = (V, M ┼ N). Since M and N are both matchings, each vertex of V is an endpoint of at most one edge from M and an endpoint of at most one edge from N. Thus each connected component of G' forms a simple path (possibly a cycle) with edges alternating between M and N. Each path that is not a cycle is either an augmenting path relative to M or an augmenting path relative to N depending on whether it has more edges from N or
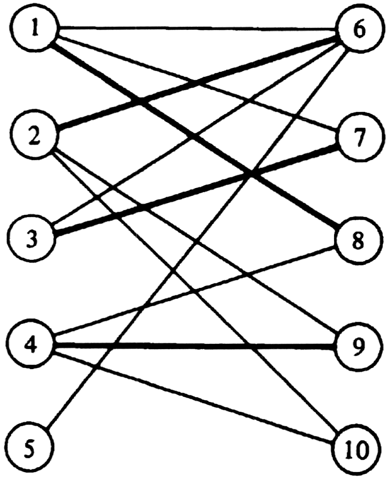
Fig. 7.18. The larger matching.
from M. Each cycle has an equal number of edges from M and N. Since ¢M¢ < ¢N¢, M ┼ N has more edges from N than M, and hence has at least one augmenting path relative to M.
We can now outline our procedure to find a maximal matching M for a graph G = (V, E).
It remains only to show how to find an augmenting path relative to a matching M. We shall do this for the simpler case where G is a bipartite graph with vertices partitioned into sets V1 and V2. We shall build an augmenting path graph for G for levels i = 0, 1, 2, . . . using a process similar to breadth-first search. Level 0 consists of all unmatched vertices from V1. At odd level i, we add new vertices that are adjacent to a vertex at level i-1, by a non-matching edge, and we also add that edge. At even level i, we add new vertices that are adjacent to a vertex at level i-1 because of an edge in the matching M, together with that edge.
We continue building the augmenting path graph level-by-level until an unmatched vertex is added at an odd level, or until no more vertices can be added. If there is an augmenting path relative to M, an unmatched vertex v will eventually be added at an odd level. The path from v to any vertex at level 0 is an augmenting path relative to M.
Example 7.10. Figure 7.19 illustrates the augmenting path graph for the graph in Fig. 7.17(a) relative to the matching in Fig. 7.18, in which we have chosen vertex 5 as the unmatched vertex at level 0. At level 1 we add the non-matching edge (5, 6). At level 2 we add the matching edge (6, 2). At level 3 we can add either of the non-matching edges (2, 9) or (2, 10). Since both vertices 9 and 10 are currently unmatched, we can terminate the construction of the augmenting path graph after the addition of either one of these vertices. Both paths 9, 2, 6, 5 and 10, 2, 6, 5 are augmenting paths relative to the matching in Fig. 7.18.
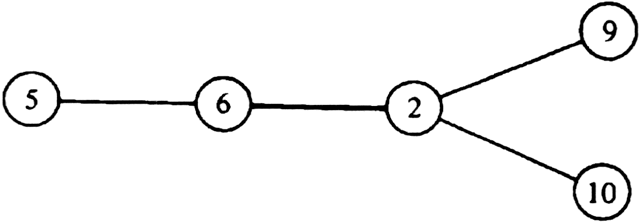
Fig. 7.19. Augmenting path graph.
Suppose G has n vertices and e edges. Constructing the augmenting path graphs for a given matching takes O(e) time if we use an adjacency list representation for edges. Thus, to find each new augmenting path takes O(e) time. To find a maximal matching, we construct at most n/2 augmenting paths, since each enlarges the current matching by at least one edge. Therefore, a maximal matching may be found in O(ne) time for a bipartite graph G.
| 7.1 | Describe an algorithm to insert and delete edges in the adjacency list representation for an undirected graph. Remember that an edge (i, j) appears on the adjacency list for both vertex i and vertex j. |
|---|---|
| 7.2 | Modify the adjacency list representation for an undirected graph so that the first edge on the adjacency list for a vertex can be deleted in constant time. Write an algorithm to delete the first edge at a vertex using your new representation. Hint. How do you arrange that the two cells representing edge (i, j) can be found quickly from one another? |
| 7.3 | Consider the graph of Fig. 7.20.
Fig. 7.20. A graph. |
| 7.4 | Let T be a depth-first spanning tree and B be the back edges for a
connected undirected graph G = (V, E).
|
| *7.5 | Let G = (V, E) be a graph. Let R be a relation on V such that u R v if and only if u and v lie on a common (not necessarily simple) cycle. Prove that R is an equivalence relation on V. |
| 7.6 | Implement both Prim's algorithm and Kruskal's algorithm. Compare the running times of your programs on a set of "random" graphs. |
| 7.7 | Write a program to find all the connected components of a graph. |
| 7.8 | Write an O(n) program to determine whether a graph of n vertices has a cycle. |
| 7.9 | Write a program to enumerate all simple cycles of a graph. How many such cycles can there be? What is the time complexity of your program? |
| 7.10 | Show that all edges in a breadth-first search are either tree edges or cross edges. |
| 7.11 | Implement the algorithm for finding articulation points discussed in Section 7.4. |
| *7.12 | Let G = (V, E) be a complete graph, that is, a graph in which there is an edge between every pair of distinct vertices. Let G' = (V, E') be a directed graph in which E' is E with each edge given an arbitrary orientation. Show that G' has a directed path that includes every vertex exactly once. |
| **7.13 | Show that an n-vertex complete graph has nn-2 spanning trees. |
| 7.14 | Find all maximal matchings for the graph of Fig. 7.16. |
| 7.15 | Write a program to find a maximal matching for a bipartite graph. |
| 7.16 | Let M be a matching and let m be the number of edges in a maximal
matching.
|
| *7.17 | Prove that a graph is bipartite if and only if it has no odd length cycles. Give an example of a non-bipartite graph for which the augmenting path graph technique of Section 7.5 no longer works. |
| 7.18 | Let M and N be matchings in a bipartite graph with ¢M¢ < ¢N¢. Prove that M ┼ N has at least ¢N¢ - ¢M¢ vertex disjoint augmenting paths relative to M. |
Methods for constructing minimal spanning trees have been studied since at least Boruvka [1926]. The two algorithms given in this chapter are based on Kruskal [1956] and Prim [1957]. Johnson [1975] shows how k-ary partially ordered trees can be used to implement Prim's algorithm. Cheriton and Tarjan [1976] and Yao [1975] present O(e 1og log n) spanning tree algorithms. Tarjan [1981] provides a comprehensive survey and history of spanning tree algorithms.
Hopcroft and Tarjan [1973] and Tarjan [1972] popularized the use of depth-first search in graph algorithms. The biconnected components algorithm is from there.
Graph matching was studied by Hall [1948] and
augmenting paths by
Berge [1957] and by Edmonds [1965]. Hopcroft and Karp [1973] give an
O(n2.5) algorithm for maximal matching in bipartite graphs, and Micali and
Vazirani [1980] give an
 algorithm for maximal matching in
general graphs. Papadimitriou and Steiglitz [1982] contains a good discussion
of general matching.
algorithm for maximal matching in
general graphs. Papadimitriou and Steiglitz [1982] contains a good discussion
of general matching.
† Unless otherwise stated, we shall assume an edge is always a pair of distinct vertices.
† Note that MERGE and FIND are defined slightly differently from Section 5.5, since C is a parameter telling where A and B can be found.
‡We can initialize a partially ordered tree of e elements in O(e) time if we do it all at once. We discuss this technique in Section 8.4, and we should probably use it here, since if many fewer than e edges are examined before the minimum-cost spanning tree is found, we may save significant time.