In this chapter we shall study some of the most fundamental abstract data types. We consider lists, which are sequences of elements, and two special cases of lists: stacks, where elements are inserted and deleted at one end only, and queues, where elements are inserted at one end and deleted at the other. We then briefly study the mapping or associative store, an ADT that behaves as a function. For each of these ADT's we consider several implementations and compare their relative merits.
Lists are a particularly flexible structure because they can grow and shrink on demand, and elements can be accessed, inserted, or deleted at any position within a list. Lists can also be concatenated together or split into sublists. Lists arise routinely in applications such as information retrieval, programming language translation, and simulation. Storage management techniques of the kind we discuss in Chapter 12 use list-processing techniques extensively. In this section we shall introduce a number of basic list operations, and in the remainder of this chapter present data structures for lists that support various subsets of these operations efficiently.
Mathematically, a list is a sequence of zero or more elements of a given type (which we generally call the elementtype). We often represent such a list by a comma-separated sequence of elements
al, a2, . . . ,an
where n ł 0, and each ai is of type elementtype. The number n of elements is said to be the length of the list. Assuming n ł 1, we say that a1 is the first element and an is the last element. If n = 0, we have an empty list, one which has no elements.
An important property of a list is that its elements can be linearly ordered according to their position on the list. We say ai precedes ai+1 for i = 1, 2, . . . , n-1, and ai follows ai-1 for i = 2, 3, . . . ,n. We say that the element ai is at position i. It is also convenient to postulate the existence of a position following the last element on a list. The function END(L) will return the position following position n in an n-element list L. Note that position END(L) has a distance from the beginning of the list that varies as the list grows or shrinks, while all other positions have a fixed distance from the beginning of the list.
To form an abstract data type from the mathematical notion of a list we must define a set of operations on objects of type LIST.† As with many other ADT's we discuss in this book, no one set of operations is suitable for all applications. Here, we shall give one representative set of operations. In the next section we shall offer several data structures to represent lists and we shall write procedures for the typical list operations in terms of these data structures.
To illustrate some common operations on lists, let us consider a typical application in which we have a mailing list from which we wish to purge duplicate entries. Conceptually, this problem can be solved quite simply: for each item on the list, remove all equivalent following items. To present this algorithm, however, we need to define operations that find the first element on a list, step through all successive elements, and retrieve and delete elements.
We shall now present a representative set of list operations. In what follows, L is a list of objects of type elementtype, x is an object of that type, and p is of type position. Note that "position" is another data type whose implementation will vary for different list implementations. Even though we informally think of positions as integers, in practice, they may have another representation.
type
elementtype = record
acctno: integer;
name: packed array [1..20] of char;
address: packed array [1..50] of char
end
then we might want same(x, y) to be true whenever
x.acctno=y.acctno.†
Figure 2.1 shows the code for PURGE. The variables p and q are used to represent two positions in the list. As the program proceeds, duplicate copies of any elements to the left of position p have been deleted from the list. In one iteration of the loop (2)-(8), q is used to scan the list following position p to delete any duplicates of the element at position p. Then p is moved to the next position and the process is repeated.
In the next section we shall provide appropriate declarations for LIST and position, and implementations for the operations so that PURGE becomes a working program. As written, the program is independent of the manner in which lists are represented so we are free to experiment with various list implementations.
procedure PURGE ( var L: LIST );
{ PURGE removes duplicate elements from list L }
var
p, q: position; { p will be the "current" position
in L, and q will move ahead to find equal elements }
begin
(1) p := FIRST(L);
(2) while p <> END(L) do begin
(3) q := NEXT(p, L);
(4) while q <> END(L) do
(5) if same(RETRIEVE(p, L), RETRIEVE(q,
L)) then
(6) DELETE(q, L)
else
(7) q := NEXT(q, L);
(8) p := NEXT(p, L)
end
end; { PURGE }
Fig. 2.1. Program to remove duplicates.
A point worth observing concerns the body of the inner loop, lines (4)-(7) of Fig. 2.1. When we delete the element at position q at line (6), the elements that were at positions q+1, q+2, . . . , and so on, move up one position in the list. In particular, should q happen to be the last position on L, the value of q would become END(L). If we then executed line (7), NEXT(END(L), L) would produce an undefined result. Thus, it is essential that either (6) or (7), but never both, is executed between the tests for q = END(L) at line (4).
In this section we shall describe some data structures that can be used to represent lists. We shall consider array, pointer, and cursor implementations of lists. Each of these implementations permits certain list operations to be done more efficiently than others.
In an array implementation of a list, the elements are stored in contiguous cells of an array. With this representation a list is easily traversed and new elements can be appended readily to the tail of the list. Inserting an element into the middle of the list, however, requires shifting all following elements one place over in the array to make room for the new element. Similarly, deleting any element except the last also requires shifting elements to close up the gap.
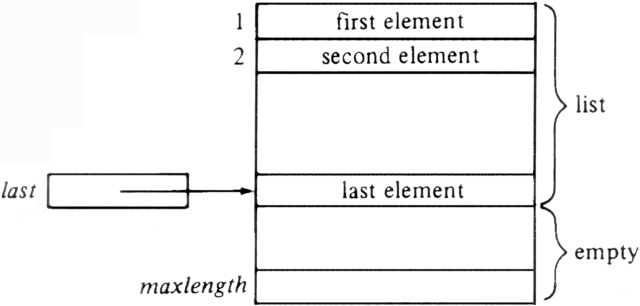
Fig. 2.2. Array implementation of a list.
In the array implementation we define the type LIST to be a record having two fields. The first field is an array of elements whose length is sufficient to hold the maximum size list that will be encountered. The second field is an integer last indicating the position of the last list element in the array. The i th element of the list is in the ith cell of the array, for 1 Ł i Ł last, as shown in Fig. 2.2. Positions in the list are represented by integers, the ith position by the integer i. The function END(L) has only to return last + 1. The important declarations are:
const
maxlength = 100 { some suitable constant };
type
LIST = record
elements: array[1..maxlength] of elementtype;
last: integer
end;
position = integer;
function END ( var L: LIST ): position;†
begin
return (L.last + 1)
end; { END }
Figure 2.3 shows how we might implement the operations INSERT, DELETE, and LOCATE using this array-based implementation. INSERT moves the elements at locations p,p+1, . . . , last into locations p+1, p+2, . . . ,last+1 and then inserts the new element at location p. If there is no room in the array for an additional element, the routine error is invoked, causing its argument to be printed, followed by termination of execution of the program. DELETE removes the element at position p by moving the elements at positions p + 1, p + 2, . . . , last into positions p, p+ 1, . . . , last-1. LOCATE sequentially scans the array to look for a given element. If the element is not found, LOCATE returns last+ 1.
It should be clear how to encode the other list operations using this implementation of lists. For example, FIRST always returns 1; NEXT returns one more than its argument and PREVIOUS returns one less, each first checking that the result is in range; MAKENULL(L) sets L.last to 0.
If procedure PURGE of Fig. 2.1 is preceded by
At first, it may seem tedious writing procedures to govern all accesses to the underlying structures. However, if we discipline ourselves to writing programs in terms of the operations for manipulating abstract data types rather than making use of particular implementation details, then we can modify programs more readily by reimplementing the operations rather than searching all programs for places where we have made accesses to the underlying data structures. This flexibility can be particularly important in large software efforts, and the reader should not judge the concept by the necessarily tiny examples found in this book.
Our second implementation of lists, singly-linked cells, uses pointers to link successive list elements. This implementation frees us from using contiguous memory for storing a list and hence from shifting elements to make room for new elements or to close up gaps created by deleted elements. However, one price we pay is extra space for pointers.
In this representation, a list is made up of cells, each cell consisting of an element of the list and a pointer to the next cell on the list. If the list is a1, a2, . . . , an, the cell holding ai has a pointer to the cell holding ai+1, for
procedure INSERT ( x: elementtype; p: position; var L:
LIST );
{ INSERT places x at position p in list L }
var
q: position;
begin
if L.last > = maxlength then
error('list is full')
else if (p > L.last + 1) or (p < 1) then
error('position does not exist')
else begin
for q := L.last downto p do
{ shift elements at p, p + 1, . . . down one position }
L.elements[q + 1 ]: = L.elements[q];
L.last := L.last + 1;
L.elements[p] := x
end
end; { INSERT }
procedure DELETE ( p: position; var L: LIST );
{ DELETE removes the element at position p of list L }
var
q: position;
begin
if (p > L.last) or (p < 1) then
error('position does not exist')
else begin
L.last := L.last - 1;
for q := p to L.last do
{ shift elements at p + 1, p + 2,... up one position }
L.elements[q] := L.elements[q + 1]
end
end; { DELETE }
function LOCATE ( x: elementtype; L: LIST ): position;
{ LOCATE returns the position of x on list L }
var
q: position;
begin
for q := 1 to L.last do
if L.elements[q] = x then
return (q);
return (L.last + 1) { if not found }
end; { LOCATE }
Fig. 2.3. Array-based implementation of some list operations.
i = 1, 2 , . . . , n-1. The cell holding an has a nil pointer. There is also a header cell that points to the cell holding a1; the header holds no element.† In the case of an empty list, the header's pointer is nil, and there are no other cells. Figure 2.4 shows a linked list of this form.

Fig. 2.4. A linked list.
For singly-linked lists, it is convenient to use a definition of position that is somewhat different than the definition of position in an array implementation. Here, position i will be a pointer to the cell holding the pointer to ai for i = 2, 3 , . . . , n. Position 1 is a pointer to the header, and position END(L) is a pointer to the last cell of L.
The type of a list happens to be the same as that of a position -- it is a pointer to a cell, the header in particular. We can formally define the essential parts of a linked list data structure as follows.
type
celltype = record
element: elementtype;
next: celltype
end;
LIST = celltype;
position = celltype;
The function END(L) is shown in Fig. 2.5. It works by moving pointer q down the list from the header, until it reaches the end, which is detected by the fact that q points to a cell with a nil pointer. Note that this implementation of END is inefficient, as it requires us to scan the entire list every time we need to compute END(L). If we need to do so frequently, as in the PURGE program of Fig. 2.1, we could either
function END ( L: LIST ): position;
{ END returns a pointer to the last cell of L }
var
q: position;
begin
(1) q := L;
(2) while q.next <> nil
do
(3) q := q.next;
(4) return (q)
end; { END }
Fig. 2.5. The function END.
Figure 2.6 contains routines for the four operations INSERT, DELETE, LOCATE, and MAKENULL using this pointer implementation of lists. The other operations can be implemented as one-step routines, with the exception of PREVIOUS, which requires a scan of the list from the beginning. We leave these other routines as exercises. Note that many of the commands do not use parameter L, the list, and we omit it from those that do not.
The mechanics of the pointer manipulations of the INSERT procedure in Fig. 2.6 are shown in Fig. 2.7. Figure 2.7(a) shows the situation before executing INSERT. We wish to insert a new element in front of the cell containing b, so p is a pointer to the list cell that contains the pointer to b. At line (1), temp is set to point to the cell containing b. At line (2) a new list cell is created and the next field of the cell containing a is made to point to this cell. At line (3) the element field of the newly-created cell is made to hold x, and at line (4) the next field is given the value of temp, thus making it point to the cell containing b. Figure 2.7(b) shows the result of executing INSERT. The new pointers are shown dashed, and marked with the step at which they were created.
The DELETE procedure is simpler. Figure 2.8 shows the pointer manipulations of the DELETE procedure in Fig. 2.6. Old pointers are solid and the new pointers dashed.
We should note that a position in a linked-list implementation of a list behaves differently from a position in an array implementation. Suppose we have a list with three elements a, b, c and a variable p, of type position, which currently has position 3 as its value; i.e., it points to the cell holding b, and thus represents the position of c. If we execute a command to insert x at position 2, the list becomes a, x, b, c, and element b now occupies position 3. If we use the array implementation of lists described earlier, b and c would be moved down the array, so b would indeed occupy the third position.
procedure INSERT ( x: elementtype; p: position);
var
temp : position;
begin
(1) temp := p .next;
(2) new(p .next );
(3) p .next .element := x;
(4) p .next .next := temp
end; { INSERT }
procedure DELETE ( p: position );
begin
p .next := p .next .next
end; { DELETE }
function LOCATE ( x: elementtype; L: LIST ): position;
var
p: position;
begin
p := L;
while p .next <> nil
do
if p .next .element = x then
return (p)
else
p := p .next;
return (p) { if not found }
end; { LOCATE }
function MAKENULL ( var L: LIST ) : position;
begin
new(L);
L .next := nil;
return (L )
end; { MAKENULL }
Fig. 2.6. Some operations using the linked-list implementation.
However, if the linked-list implementation is used, the value of p, which is a pointer to the cell containing b, does not change because of the insertion, so afterward, the value of p is "position 4," not 3. This position variable must be updated, if it is to be used subsequently as the position of b.†
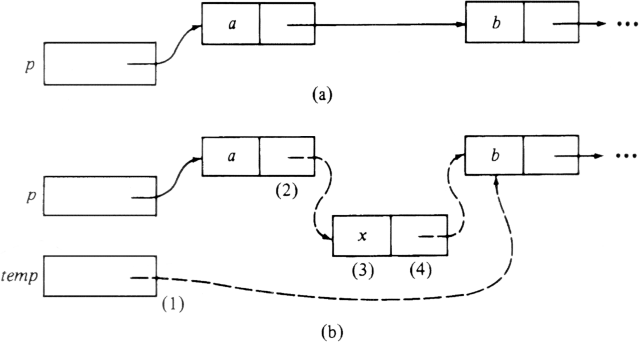
Fig. 2.7. Diagram of INSERT.

Fig. 2.8. Diagram of DELETE.
We might wonder whether it is best to use a pointer-based or array-based implementation of lists in a given circumstance. Often the answer depends on which operations we intend to perform, or on which are performed most frequently. Other times, the decision rests on how long the list is likely to get. The principal issues to consider are the following.
Some languages, such as Fortran and Algol, do not have pointers. If we are working with such a language, we can simulate pointers with cursors, that is, with integers that indicate positions in arrays. For all the lists of elements whose type is elementtype, we create one array of records; each record consists of an element and an integer that is used as a cursor. That is, we define
var
SPACE: array [1..maxlength] of record
element: elementtype;
next: integer
end
If L is a list of elements, we declare an integer variable say Lhead, as a header for L. We can treat Lhead as a cursor to a header cell in SPACE with an empty element field. The list operations can then be implemented as in the pointer-based implementation just described.
Here, we shall describe an alternative implementation that avoids the use of header cells by making special cases of insertions and deletions at position 1. This same technique can also be used with pointer-based linked-lists to avoid the use of header cells. For a list L, the value of SPACE[Lhead].element is the first element of L. The value of SPACE[Lhead].next is the index of the cell containing the second element, and so on. A value of 0 in either Lhead or the field next indicates a "nil pointer"; that is, there is no element following.
A list will have type integer, since the header is an integer variable that represents the list as a whole. Positions will also be of type integer. We adopt the convention that position i of list L is the index of the cell of SPACE holding element i-1 of L, since the next field of that cell will hold the cursor to element i. As a special case, position 1 of any list is represented by 0. Since the name of the list is always a parameter of operations that use positions, we can distinguish among the first positions of different lists. The position END(L) is the index of the last element on L.
Figure 2.9 shows two lists, L = a, b, c and M = d, e, sharing the array SPACE, with maxlength = 10. Notice that all the cells of the array that are not on either list are linked on another list called available. This list is necessary so we can obtain an empty cell when we want to insert into some list, and so we can have a place to put deleted cells for later reuse.
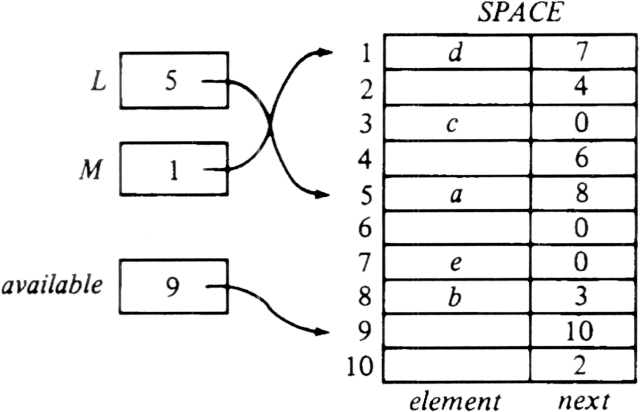
Fig. 2.9. A cursor implementation of linked lists.
To insert an element x into a list L we take the first cell in the available list and place it in the correct position of list L. Element x is then placed in the element field of this cell. To delete an element x from list L we remove the cell containing x from L and return it to the beginning of the available list. These two actions can be viewed as special cases of the act of taking a cell C pointed to by one cursor p and causing another cursor q to point to C, while making p point where C had pointed and making C point where q had pointed. Effectively, C is inserted between q and whatever q pointed to. For example, if we delete b from list L in Fig. 2.9, C is row 8 of SPACE, p is SPACE[5].next, and q is available. The cursors before (solid) and after (dashed) this action are shown in Fig. 2.10, and the code is embodied in the function move of Fig. 2.11, which performs the move if C exists and returns false if C does not exist.
Figure 2.12 shows the procedures INSERT and DELETE, and a procedure initialize that links the cells of the array SPACE into an available space list. These procedures omit checks for errors; the reader may insert them as an exercise. Other operations are left as exercises and are similar to those for pointer-based linked lists.
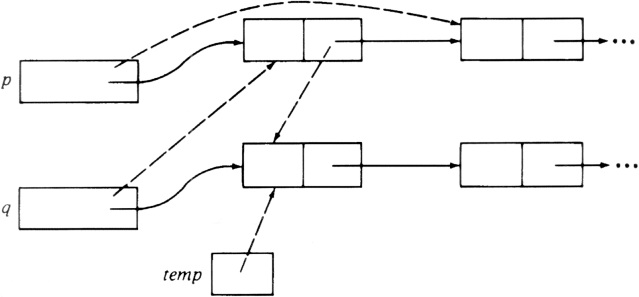
Fig. 2.10. Moving a cell C from one list to another.
function move ( var p, q: integer ): boolean;
{ move puts cell pointed to by p ahead of cell pointed to by q }
var
temp: integer;
begin
if p = 0 then begin { cell nonexistent }
writeln('cell does not exist');
return (false)
end
else begin
temp := q;
q := p;
p := SPACE[q ].next;
SPACE[q ].next := temp;
return (true)
end
end; { move }
Fig. 2.11. Code to move a cell.
In a number of applications we may wish to traverse a list both forwards and backwards efficiently. Or, given an element, we may wish to determine the preceding and following elements quickly. In such situations we might wish
procedure INSERT ( x: elementtype; p: position; var L:
LIST );
begin
if p = 0 then begin
{ insert at first position }
if move(available, L) then
SPACE[L].element := x
end
else { insert at position other than first }
if move(available, SPACE[p].next)
then
{ cell for x now pointed to by SPACE[p].next }
SPACE[SPACE[p].next].element :=
x
end; { INSERT }
procedure DELETE ( p: position; var L: LIST );
begin
if p = 0 then
move(L, available)
else
move(SPACE[p].next, available)
end; { DELETE }
procedure initialize;
{ initialize links SPACE into one available list }
var
i: integer;
begin
for i := maxsize - 1 downto 1 do
SPACE[i].next := i + 1;
available := 1;
SPACE[maxsize].next := 0 { mark end of available list }
end; { initialize }
Fig. 2.12. Some procedures for cursor-based linked lists.
to give each cell on a list a pointer to both the next and previous cells on the list, as suggested by the doubly-linked list in Fig. 2.13. Chapter 12 mentions some specific situations where doubly-linked lists are essential for efficiency.

Fig. 2.13. A doubly linked list.
Another important advantage of doubly linked lists is that we can use a pointer to the cell containing the ith element of a list to represent position i, rather than using the less natural pointer to the previous cell. The only price we pay for these features is the presence of an additional pointer in each cell, and somewhat lengthier procedures for some of the basic list operations. If we use pointers (rather than cursors), we may declare cells consisting of an element and two pointers by
type
celltype = record
element: elementtype;
next, previous: celltype
end;
position = celltype;
A procedure for deleting an element at position p in a doubly-linked list is given in Fig. 2.14. Figure 2.15 shows the changes in pointers caused by Fig. 2.14, with old pointers drawn solid and new pointers drawn dashed, on the assumption that the deleted cell is neither first nor last.† We first locate the preceding cell using the previous field. We make the next field of this cell point to the cell following the one in position p. Then we make the previous field of this following cell point to the cell preceding the one in position p. The cell pointed to by p becomes useless and should be reused automatically by the Pascal run-time system if needed.
procedure DELETE (var p: position );
begin
if p.previous <> nil
then
{ deleted cell not the first }
p.previous.next: = p.next;
if p.next <> nil
then
{ deleted cell not the last }
p.next.previous : = p.previous
end; { DELETE }
Fig. 2.14. Deletion from a doubly linked list.
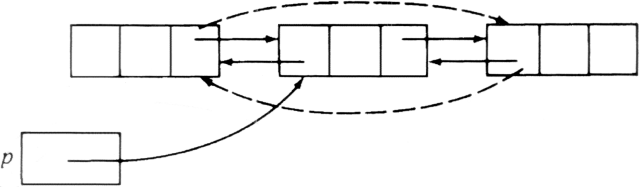
Fig. 2.15. Pointer changes for implementation of a deletion.
A stack is a special kind of list in which all insertions and deletions take place at one end, called the top. Other names for a stack are "pushdown list," and "LIFO" or "last-in-first-out" list. The intuitive model of a stack is a pile of poker chips on a table, books on a floor, or dishes on a shelf, where it is only convenient to remove the top object on the pile or add a new one above the top. An abstract data type in the STACK family often includes the following five operations.
Text editors also have a kill character, whose effect is to cancel all previous characters on the current line. For the purposes of this example, we shall use '@' as the kill character.
A text editor can process a line of text using a stack. The editor reads one character at a time. If the character read is neither the kill nor the erase character, it pushes the character onto the stack. If the character read is the erase character, the editor pops the stack, and if it is the kill character, the editor makes the stack empty. A program that executes these actions is shown in Fig. 2.16.
procedure EDIT;
var
S: STACK;
c: char;
begin
MAKENULL(S);
while not eoln do begin
read(c);
if c = '#' then
POP(S)
else if c = '@' then
MAKENULL(S)
else { c is an ordinary character }
PUSH(c, S)
end;
print S in reverse order
end; { EDIT }
Fig. 2.16. Program to carry out effects of erase and kill characters.
In this program, the type of STACK must be declared as a list of characters. The process of writing the stack in reverse order in the last line of the program is a bit tricky. Popping the stack one character at a time gets the line in reverse order. Some stack implementations, such as the array-based implementation to be discussed next, allow us to write a simple procedure to print the stack from the bottom. In general, however, to reverse a stack, we must pop each element and push it onto another stack; the characters can then be popped from the second stack and printed in the order they are popped.
Every implementation of lists we have described works for stacks, since a stack with its operations is a special case of a list with its operations. The linked-list representation of a stack is easy, as PUSH and POP operate only on the header cell and the first cell on the list. In fact, headers can be pointers or cursors rather than complete cells, since there is no notion of "position" for stacks, and thus no need to represent position 1 in a way analogous to other positions.
However, the array-based implementation of lists we gave in Section 2.2 is not a particularly good one for stacks, as every PUSH or POP requires moving the entire list up or down, thus taking time proportional to the number of elements on the stack. A better arrangement for using an array takes account of the fact that insertions and deletions occur only at the top. We can anchor the bottom of the stack at the bottom (high-indexed end) of the array, and let the stack grow towards the top (low-indexed end) of the array. A cursor called top indicates the current position of the first stack element. This idea is shown in Fig. 2.17.
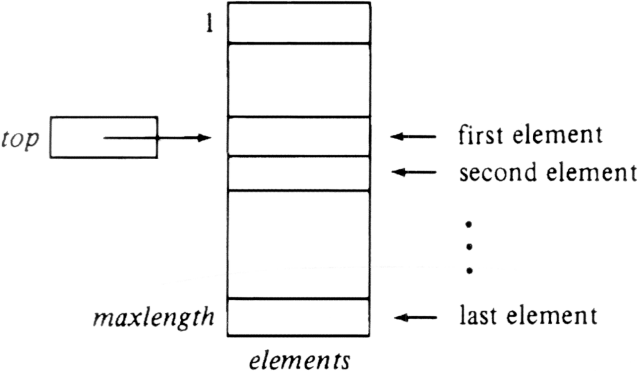
Fig. 2.17. An array implementation of a stack.
For this array-based implementation of stacks we define the abstract data type STACK by
type
STACK = record
top: integer;
elements: array[1..maxlength] of elementtype
end;
An instance of the stack consists of the sequence elements[top],
elements[top+1] , . . . , elements[maxlength]. Note that if top =
maxlength +
1, then the stack is empty.
The five typical stack operations are implemented in Fig. 2.18. Note that for TOP to return an elementtype, that type must be legal as the result of a function. If not, TOP must be a procedure that modifies its second argument by assigning it the value TOP(S), or a function that returns a pointer to elementtype.
procedure MAKENULL ( var S: STACK );
begin
S.top := maxlength + 1
end; { MAKENULL }
function EMPTY ( S: STACK ): boolean;
begin
if S.top > maxlength then
return (true)
else
return (false)
end; { EMPTY }
function TOP ( var S: STACK ) : elementtype;
begin
if EMPTY(S) then
error('stack is empty')
else
return(S.elements[S.top])
end; { TOP }
procedure POP ( var S: STACK );
begin
if EMPTY(S) then
error('stack is empty')
else
S.top := S.top + 1
end; { POP }
procedure PUSH ( x: elementtype; var S: STACK );
begin
if S.top = 1 then
error('stack is full')
else begin
S.top := S.top - 1;
S.elements[S.top]: = x
end
end; { PUSH }
Fig. 2.18. Operations on stacks
A queue is another special kind of list, where items are inserted at one end (the rear) and deleted at the other end (the front). Another name for a queue is a "FIFO" or "first-in first-out" list. The operations for a queue are analogous to those for a stack, the substantial differences being that insertions go at the end of the list, rather than the beginning, and that traditional terminology for stacks and queues is different. We shall use the following operations on queues.
As for stacks, any list implementation is legal for queues. However, we can take advantage of the fact that insertions are only done at the rear to make ENQUEUE efficient. Instead of running down the list from beginning to end each time we wish to enqueue something, we can keep a pointer (or cursor) to the last element. As for all kinds of lists, we also keep a pointer to the front of the list; for queues that pointer is useful for executing FRONT and DEQUEUE commands. In Pascal, we shall use a dummy cell as a header and have the front pointer point to it. This convention allows us to handle an empty queue conveniently.
Here we shall develop an implementation for queues that is based on Pascal pointers. The reader may develop a cursor-based implementation that is analogous, but we have available, in the case of queues, a better array-oriented representation than would be achieved by mimicking pointers with cursors directly. We shall discuss this so-called "circular array" implementation at the end of this section. To proceed with the pointer-based implementation, let us define cells as before:
type
celltype = record
element: elementtype;
next: celltype
end;
Then we can define a list to consist of pointers to the front and rear of the
queue. The first cell on a queue is a header cell in which the element field is
ignored. This convention, as mentioned above, allows a simple representation
for an empty queue. We define:
type
QUEUE = record
front, rear: celltype
end;
Figure 2.19 shows programs for the five queue operations. In MAKENULL
the first statement new(Q.front) allocates a variable of type celltype and
assigns its address to Q.front. The second statement puts nil into the next
field of that cell. The third statement makes the header both the first and last
cell of the queue.
The procedure DEQUEUE(Q) deletes the first element of Q by disconnecting the old header from the queue. The first element on the list becomes the new dummy header cell.
Figure 2.20 shows the results created by the sequence of commands MAKENULL(Q), ENQUEUE(x, Q), ENQUEUE(y, Q), DEQUEUE(Q). Note that after dequeueing, the element x being in the element field of the header cell, is no longer considered part of the queue.
The array representation of lists discussed in Section 2.2 can be used for queues, but it is not very efficient. True, with a pointer to the last element, we can execute ENQUEUE in a fixed number of steps, but DEQUEUE, which removes the first element, requires that the entire queue be moved up one position in the array. Thus DEQUEUE takes W(n) time if the queue has length n.
To avoid this expense, we must take a different viewpoint. Think of an array as a circle, where the first position follows the last, as suggested in Fig. 2.21. The queue is found somewhere around the circle in consecutive positions,† with the rear of the queue somewhere clockwise from the front. To enqueue an element, we move the Q.rear pointer one position clockwise and write the element in that position. To dequeue, we simply move Q.front one position clockwise. Thus, the queue migrates in a clockwise direction as we enqueue and dequeue elements. Observe that the procedures ENQUEUE and DEQUEUE can be written to take some constant number of steps if the circular array model is used.
There is one subtlety that comes up in the representation of Fig 2.21 and in any minor variation of that strategy (e.g., if Q.rear points one position clockwise of the last element, rather than to that element itself). The problem is that there is no way to tell an empty queue from one that occupies the entire circle, short of maintaining a bit that is true if and only if the queue is empty. If we are not willing to maintain this bit, we must prevent the queue from ever filling the entire array.
To see why, suppose the queue of Fig. 2.21 had maxlength elements. Then Q.rear would point one position counterclockwise of Q.front. What if the queue were empty? To see how an empty queue is represented, let us first consider a queue of one element. Then Q.front and Q.rear point to the same position. If we dequeue the one element, Q.front moves one position
procedure MAKENULL ( var Q: QUEUE );
begin
new(Q.front); { create header cell }
Q.front.next := nil;
Q.rear := Q.front { header is both first and last cell }
end; { MAKENULL }
function EMPTY ( Q: QUEUE): boolean;
begin
if Q.front = Q.rear then
return (true)
else
return (false)
end; { EMPTY }
function FRONT ( Q: QUEUE ): elementtype;
begin
if EMPTY(Q) then
error('queue is empty')
else
return (Q.front.next.element)
end; { FRONT }
procedure ENQUEUE ( x: elementtype; var Q: QUEUE );
begin
new(Q.rear.next); { add new cell to
rear of queue }
Q.rear: = Q.rear.next;
Q.rear.element := x;
Q.rear.next := nil
end; { ENQUEUE }
procedure DEQUEUE ( var Q: QUEUE );
begin
if EMPTY(Q) then
error('queue is empty')
else
Q.front := Q.front.next
end; { DEQUEUE }
Fig. 2.19. Implementation of queue commands.
clockwise; forming an empty queue. Thus an empty queue has Q.rear one position counterclockwise of Q.front, which is exactly the same relative position as when the queue had maxlength elements. We thus see that even though the array has maxlength places, we cannot let the queue grow longer than maxlength-1, unless we introduce another mechanism to distinguish empty queues.
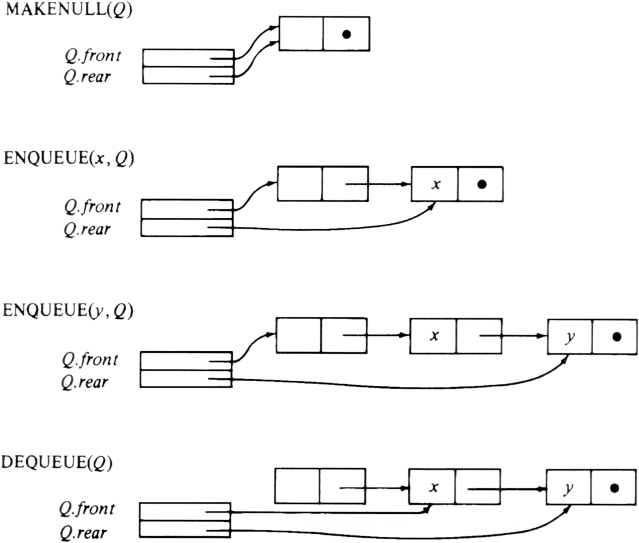
Fig. 2.20. A sequence of queue operations.
Let us now write the five queue commands using this representation for a queue. Formally, queues are defined by:
type
QUEUE = record
element: array[1..maxlength] of elementtype;
front, rear: integer
end;
The commands appear in Fig. 2.22. The function addone(i) adds one to position i in the circular sense.
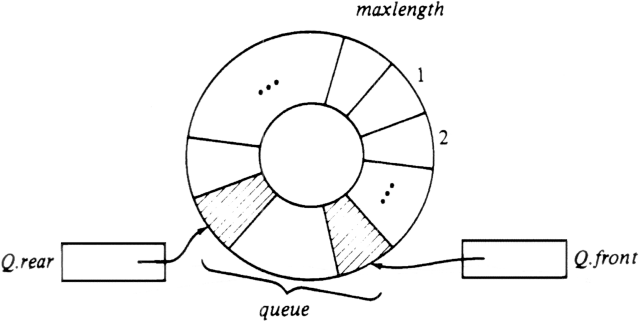
Fig. 2.21. A circular implementation of queues.
A mapping or associative store is a function from elements of one type, called the domain type to elements of another (possibly the same) type, called the range type. We express the fact that the mapping M associates element r of range type rangetype with element d of domain type domaintype by M(d) = r.
Certain mappings such as square(i) = i2 can be implemented easily as a Pascal function by giving an arithmetic expression or other simple means for calculating M(d) from d. However, for many mappings there is no apparent way to describe M(d) other than to store for each d the value of M(d). For example, to implement a payroll function that associates with each employee a weekly salary seems to require that we store the current salary for each employee. In the remainder of this section we describe a method of implementing functions such as the "payroll" function.
Let us consider what operations we might wish to perform on a mapping M. Given an element d of some domain type, we may wish to obtain M(d) or know whether M(d) is defined (i.e., whether d is currently in the domain of M). Or we may wish to enter new elements into the current domain of M and state their associated range values. Alternatively, we might wish to change the value of M(d). We also need a way to initialize a mapping to the null mapping, the mapping whose domain is empty. These operations are summarized by the following three commands.
function addone ( i: integer ): integer;
begin
return (( i mod maxlength ) + 1)
end; { addone }
procedure MAKENULL ( var Q: QUEUE );
begin
Q.front := 1;
Q.rear := maxlength
end; { MAKENULL }
function EMPTY ( var Q: QUEUE ): boolean;
begin
if addone(Q.rear) = Q.front then
return (true)
else
return (false)
end; { EMPTY }
function FRONT ( var Q: QUEUE ): elementtype;
begin
if EMPTY(Q) then
error('queue is empty')
else
return (Q.elements[Q.front])
end; { FRONT }
procedure ENQUEUE ( x: elementtype; var Q: QUEUE );
begin
if addone (addone(Q.rear)) = Q.front then
error('queue is full')
else begin
Q.rear := addone(Q.rear);
Q.elements[Q.rear] := x
end
end; { ENQUEUE )
procedure DEQUEUE ( var Q: QUEUE );
begin
if EMPTY(Q) then
error('queue is empty')
else
Q.front := addone(Q.front)
end; { DEQUEUE }
Fig. 2.22. Circular queque implementation.
Many times, the domain type of a mapping will be an elementary type that can be used as an index type of an array. In Pascal, the index types include all the finite subranges of integers, like 1..100 or 17..23, the type char and subranges of char like 'A'..'Z', and enumerated types like (north, east, south, west). For example, a cipher-breaking program might keep a mapping crypt, with 'A'..'Z' as both its domain type and its range type, such that crypt (plaintext) is the letter currently guessed to stand for the letter plaintext.
Such mappings can be implemented simply by arrays, provided there is some range type value that can stand for "undefined." For example, the above mapping crypt might be defined to have range type char, rather than 'A'..'Z', and '?' could be used to denote "undefined."
Suppose the domain and range types are domaintype and rangetype, and domaintype is a basic Pascal type. Then we can define the type MAPPING (strictly speaking, mapping from domaintype to rangetype) by the declaration
type
MAPPING = array[domaintype] of rangetype;
On the assumption that "undefined" is a constant of rangetype, and that
firstvalue and lastvalue are the first and last values in domaintype,† we can
implement the three commands on mappings as in Fig. 2.23.
There are many possible implementations of mappings with finite domains. For example, hash tables are an excellent choice in many situations, but one whose discussion we shall defer to Chapter 4. Any mapping with a finite domain can be represented by the list of pairs (d1, r1), (d2, r2), . . . , (dk, rk), where d1, d2, . . . , dk are all the current members of the domain, and ri is the value that the mapping associates with di, for i = 1, 2 , . . . ,k. We can then use any implementation of lists we choose for this list of pairs.
To be precise, the abstract data type MAPPING can be implemented by lists of elementtype, if we define
type
elementtype = record
domain: domaintype;
range: rangetype
end;
and then define MAPPING as we would define type LIST (of elementtype) in
procedure MAKENULL ( var M: MAPPING );
var
i: domaintype;
begin
for i := firstvalue to lastvalue do
M[i] := undefined
end; { MAKENULL }
procedure ASSIGN ( var M: MAPPING;
d: domaintype; r: rangetype );
begin
M[d] := r
end; { ASSIGN }
function COMPUTE ( var M: MAPPING;
d: domaintype; var r: rangetype ): boolean;
begin
if M[d] = undefined then
return (false)
else begin
r := M[d];
return (true)
end
end; { COMPUTE }
Fig. 2.23. Array implementation of mappings.
whatever implementation of lists we choose. The three mapping commands are defined in terms of commands on type LIST in Fig. 2.24.One important application of stacks is in the implementation of recursive procedures in programming languages. The run-time organization for a programming language is the set of data structures used to represent the values of the program variables during program execution. Every language that, like Pascal, allows recursive procedures, uses a stack of activation records to record the values for all the variables belonging to each active procedure of a program. When a procedure P is called, a new activation record for P is placed on the stack, regardless of whether there is already another activation record for P on the stack. When P returns, its activation record must be on top of the stack, since P cannot return until all procedures it has called have returned to P. Thus, we may pop the activation record for this call of P to cause control to return to the point at which P was called (that point, known as the return address, was placed in P's activation record when the call to P
procedure MAKENULL ( var M: MAPPING );
{ same as for list }
procedure ASSIGN ( var M: MAPPING;
d: domaintype; r: rangetype );
var
x: elementtype; { the pair (d, r) }
p: position; { used to go from first to last position on list M }
begin
x.domain := d;
x.range := r;
p := FIRST(M);
while p <> END(M) do
if RETRIEVE(p, M).domain = d then
DELETE(p, M) { remove element with domain d }
else
p := NEXT(p, M);
INSERT(x, FIRST(M), M) { put (d, r) at front of list }
end; { ASSIGN }
function COMPUTE ( var M: MAPPING;
d: domaintype; var r: rangetype ): boolean;
var
p: position;
begin
p := FIRST(M);
while p <> END(M) do begin
if RETRIEVE(p, M).domain = d then begin
r := RETRIEVE(p, M).range;
return (true)
end;
p := NEXT(p, M)
end;
return (false) { if d is not in domain }
end; { COMPUTE }
Fig. 2.24. Mapping implementation in terms of lists.
was made).Recursion simplifies the structure of many programs. In some languages, however, procedure calls are much more costly than assignment statements, so a program may run faster by a large constant factor if we eliminate recursive procedure calls from it. We do not advocate that recursion or other procedure calls be eliminated habitually; most often the structural simplicity is well worth the running time. However, in the most frequently executed portions of programs, we may wish to eliminate recursion, and it is the purpose of this discussion to illustrate how recursive procedures can be converted to nonrecursive ones by the introduction of a user-defined stack.
Example 2.3. Let us consider recursive and nonrecursive solutions to a simplified version of the classic knapsack problem in which we are given target t and a collection of positive integer weights w1, w2 , . . . , wn. We are asked to determine whether there is some selection from among the weights that totals exactly t. For example, if t = 10, and the weights are 7, 5, 4, 4, and 1, we could select the second, third, and fifth weights, since 5+4+ 1 = 10.
The image that justifies the name "knapsack problem" is that we wish to carry on our back no more than t pounds, and we have a choice of items with given weights to carry. We presumably find the items' utility to be proportional to their weight,† so we wish to pack our knapsack as closely to the target weight as we can.
In Fig. 2.25 we see a function knapsack that operates on
an array
weights
: array [l..n] of integer.
A call to knapsack(s, i) determines whether there is a collection of the
elements in weight[i] through weight[n] that sums to exactly s, and
prints these
weights if so. The first thing knapsack does is determine if it can respond
immediately. Specifically, if s = 0, then the empty set of weights is a
solution. If s < 0, there can be no solution, and if s > 0 and i > n,
then we are
out of weights to consider and therefore cannot find a sum equal to s.
If none of these cases applies, then we simply call knapsack(s-wi, i + 1) to see if there is a solution that includes wi. If there is such a solution, then the total problem is solved, and the solution includes wi, so we print it. If there is no solution, then we call knapsack(s, i + 1) to see if there is a solution that does not use wi.
Often, we can eliminate mechanically the last call a procedure makes to itself. If a procedure P(x) has, as its last step, a call to P(y), then we can replace the call to P(y) by an assignment x := y, followed by a jump to the beginning of the code for P. Here, y could be an expression, but x must be a parameter passed by value, so its value is stored in a location private to this call to P ‡ P could have more than one parameter, of course, and if so, they are each treated exactly as x and y above.
This change works because rerunning P with the new value of x has exactly the same effect as calling P(y) and then returning from that call.
function knapsack ( target: integer; candidate: integer ): boolean;
begin
(1) if target = 0 then
(2) return (true)
(3) else if (target < 0) or (candidate > n) then
(4) return (false)
else { consider solutions with and without candidate }
(5) if knapsack(target - weights[candidate], candidate + 1)
then
begin
(6) writeln(weights[candidate]);
(7) return (true)
end
else { only possible solution is without candidate }
(8) return (knapsack(target, candidate + 1))
end; { knapsack }
Fig. 2.25. Recursive knapsack solution.
Notice that the fact that some of P's local variables have values the second time around is of no consequence. P could not use any of those values, or had we called P(y) as originally intended, the value used would not have been defined.
Another variant of tail recursion is illustrated by Fig. 2.25, where the last step of the function knapsack just returns the result of calling itself with other parameters. In such a situation, again provided the parameters are passed by value (or by reference if the same parameter is passed to the call), we can replace the call by assignments to the parameters and a jump to the beginning of the function. In the case of Fig. 2.25, we can replace line (8) by
candidate:= candidate + 1; goto beginningwhere beginning stands for a label to be assigned to statement (1). Note no change to target is needed, since it is passed intact as the first parameter. In fact, we could observe that since target has not changed, the tests of statements (1) and (3) involving target are destined to fail, and we could instead skip statements (1) and (2), test only for candidate > n at line (3), and proceed directly to line (5).
The tail recursion elimination procedure removes recursion completely only when the recursive call is at the end of the procedure, and the call has the correct form. There is a more general approach that converts any recursive procedure (or function) into a nonrecursive one, but this approach introduces a user-defined stack. In general, a cell of this stack will hold:
In the case of the function knapsack, we can do something simpler. First, observe that whenever we make a call (push a record onto the stack), candidate increases by 1. Thus, we can keep candidate as a global variable, incrementing it by one every time we push the stack and decreasing it by one when we pop.
A second simplification we can make is to keep a modified "return address" on the stack. Strictly speaking, the return address for this function is either a place in some other procedure that calls knapsack, or the call at line (5), or the call at line (8). We can represent these three conditions by a "status," which has one of three values:
If we store this status symbol as the return address, then we can treat target as a global variable. When changing from status none to included, we subtract weights[candidate] from target, and we add it back in when changing from status included to excluded. To help represent the effect of the knapsack's return indicating whether a solution has been found, we use a global winflag. Once set to true, winflag remains true and causes the stack to be popped and those weights with status included to be printed. With these modifications, we can declare our stack to be a list of statuses, by
type
statuses = (none, included, excluded);
STACK = { suitable declaration for stack of statuses }
Figure 2.26 shows the resulting nonrecursive procedure knapsack operating on
an array weights as before. Although this procedure may be faster than the
original function knapsack, it is clearly longer and more difficult to
understand. For this reason, recursion elimination should be used only when speed
is very important.
procedure knapsack ( target: integer );
var
candidate: integer;
winflag: boolean;
S: STACK;
begin
candidate := 1;
winflag := false;
MAKENULL(S);
PUSH(none, S); { initialize stack to consider weights[1] }
repeat
if winflag then begin
{ pop stack, printing weights included in solution }
if TOP(S) = included then
writeln(weights[candidate]);
candidate := candidate - 1;
POP(S)
end
else if target = 0 then begin { solution found }
winflag := true;
candidate := candidate - 1;
POP(S)
end
else if (((target < 0) and (TOP(S) = none))
or (candidate > n)) then begin
{ no solution possible with choices made }
candidate := candidate - 1;
POP(S)
end
else { no resolution yet; consider status of current candidate }
if TOP(S) = none then begin { first try including candidate }
target := target - weights[candidate];
candidate := candidate + 1;
POP(S); PUSH(included, S); PUSH(none, S)
end
else if TOP(S) = included then begin { try excluding candidate }
target := target + weights[candidate];
candidate := candidate + 1;
POP(S); PUSH(excluded, S); PUSH(none, S)
end
else begin { TOP(S) = excluded; give up on current choice }
POP(S);
candidate := candidate - 1
end
until EMPTY(S)
end; { knapsack }
Fig. 2.26. Nonrecursive knapsack procedure.
| 2.1 | Write a program to print the elements on a list. Throughout these exercises use list operations to implement your programs. |
|---|---|
| 2.2 | Write programs to insert, delete, and locate an element on a sorted
list using
|
| 2.3 | Write a program to merge
|
| 2.4 | Write a program to concatenate a list of lists. |
| 2.5 | Suppose we wish to manipulate polynomials of the form p(x) = c1xe1 + c2xe2 + . . . + cnxen, where e1 > e2 > . . . > en ł 0. Such a polynomial can be represented by a linked list in which each cell has three fields: one for the coefficient ci, one for the exponent ei, and one for the pointer to the next cell. Write a program to differentiate polynomials represented in this manner. |
| 2.6 | Write programs to add and multiply polynomials of the form in Exercise 2.5. What is the running time of your programs as a function of the number of terms? |
| *2.7 | Suppose we declare cells by
type
celltype = record
bit: 0..1;
next: celltype
end;
A binary number b1b2 . . .
bn, where each bi is 0 or 1, has numerical
value
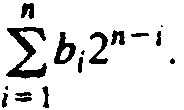 . This number can be represented by
the list b1, b2 , . . . , bn.
That list, in turn, can be represented as a linked list
of cells of type celltype. Write a procedure increment(bnumber) that
adds one to the binary number pointed to by bnumber. Hint: Make
increment recursive. . This number can be represented by
the list b1, b2 , . . . , bn.
That list, in turn, can be represented as a linked list
of cells of type celltype. Write a procedure increment(bnumber) that
adds one to the binary number pointed to by bnumber. Hint: Make
increment recursive. |
| 2.8 | Write a procedure to interchange the elements at positions p and NEXT(p) in a singly linked list. |
| *2.9 | The following procedure was intended to remove all occurrences of
element x from list L. Explain why it doesn't always work and
suggest a way to repair the procedure so it performs its intended task.
procedure delete ( x: elementtype; var L: LIST );
var
p: position;
begin
p := FIRST(L);
while p <> END(L) do begin
if RETRIEVE(p, L) = x then
DELETE(p, L);
p := NEXT(p, L)
end
end; { delete }
|
| 2.10 | We wish to store a list in an array A whose cells consist of two fields,
data to store an element and position to give the (integer) position of
the element. An integer last indicates that A[1] through A[last] are
used to hold the list. The type LIST can be defined by
type
LIST = record
last: integer;
elements: array[1..maxlength] of record
data: elementtype;
position: integer
end
end;
Write a procedure DELETE(p, L) to remove the element at position
p. Include all necessary error checks. |
| 2.11 | Suppose L is a LIST and p, q, and r are positions. As a function of
n, the length of list L, determine how many times the functions
FIRST, END, and NEXT are executed by the following program.
p := FIRST(L);
while p <> END(L) do begin
q := p;
while q <> END(L) do begin
q := NEXT(q, L);
r := FIRST(L);
while r <> q do
r := NEXT(r, L)
end;
p := NEXT(p, L)
end;
|
| 2.12 | Rewrite the code for the LIST operations assuming a linked list representation, but without a header cell. Assume true pointers are used and position 1 is represented by nil. |
| 2.13 | Add the necessary error checks in the procedure of Fig. 2.12. |
| 2.14 | Another array representation of lists is to insert as in Section 2.2, but when deleting, simply replace the deleted element by a special value "deleted," which we assume does not appear on lists otherwise. Rewrite the list operations to implement this strategy. What are the advantages and disadvantages of the approach compared with our original array representation of lists? |
| 2.15 | Suppose we wish to use an extra bit in queue records to indicate whether a queue is empty. Modify the declarations and operations for a circular queue to accommodate this feature. Would you expect the change to be worthwhile? |
| 2.16 | A dequeue (double-ended queue) is a list from which elements can be inserted or deleted at either end. Develop array, pointer, and cursor implementations for a dequeue. |
| 2.17 | Define an ADT to support the operations ENQUEUE, DEQUEUE, and ONQUEUE. ONQUEUE(x) is a function returning true or false depending on whether x is or is not on the queue. |
| 2.18 | How would one implement a queue if the elements that are to be placed on the queue are arbitrary length strings? How long does it take to enqueue a string? |
| 2.19 | Another possible linked-list implementation of queues is to use no header cell, and let front point directly to the first cell. If the queue is empty, let front = rear = nil. Implement the queue operations for this representation. How does this implementation compare with the list implementation given for queues in Section 2.4 in terms of speed, space utilization, and conciseness of the code? |
| 2.20 | A variant of the circular queue records the position of the front
element and the length of the queue.
|
| 2.21 | It is possible to keep two stacks in a single array, if one grows from position 1 of the array, and the other grows from the last position. Write a procedure PUSH(x, S) that pushes element x onto stack S, where S is one or the other of these two stacks. Include all necessary error checks in your procedure. |
| 2.22 | We can store k stacks in a single array if we use the data structure
suggested in Fig. 2.27, for the case k = 3. We push and pop from
each stack as suggested in connection with Fig. 2.17 in Section 2.3.
However, if pushing onto stack i causes TOP(i) to equal
BOTTOM(i-1), we first move all the stacks so that there is an
appropriate size gap between each adjacent pair of stacks. For
example, we might make the gaps above all stacks equal, or we might
make the gap above stack i proportional to the current size of stack i
(on the theory that larger stacks are likely to grow sooner, and we
want to postpone as long as possible the next reorganization).
|
| 2.23 | Modify the implementations of POP and ENQUEUE in Sections 2.3 and 2.4 to return the element removed from the stack or queue. What modifications must be made if the element type is not a type that can be returned by a function? |
| 2.24 | Use a stack to eliminate recursion from the following procedures.
a. function comb ( n, m: integer ): integer;
{ computes (
Fig. 2.27. Many stacks in one array.
b. procedure reverse ( var L: LIST );
{ reverse list L }
var
x: elementtype;
begin
if not EMPTY(L) then begin
x := RETRIEVE(FIRST(L), L);
DELETE(FIRST(L), L);
reverse(L);
INSERT(x, END(L), L)
end
end; { reverse }
|
| *2.25 | Can we eliminate the tail recursion from the programs in Exercise 2.24? If so, do it. |
Knuth [1968] contains additional information on the implementation of lists, stacks, and queues. A number of programming languages, such as LISP and SNOBOL, support lists and strings in a convenient manner. See Sammet [1969], Nicholls [1975], Pratt [1975], or Wexelblat [1981] for a history and description of many of these languages.
† Strictly speaking, the type is "LIST of elementtype." However, the implementations of lists we propose do not depend on what elementtype is; indeed, it is that independence that justifies the importance we place on the list concept. We shall use "LIST" rather than "LIST of elementtype," and similarly treat other ADT's that depend on the types of elements.
† In this case, if we eliminate records that are "the same" we might wish to check that the names and addresses are also equal; if the account numbers are equal but the other fields are not, two people may have inadvertently gotten the same account number. More likely, however, is that the same subscriber appears on the list more than once with distinct account numbers and slightly different names and/or addresses. In such cases, it is difficult to eliminate all duplicates.
† Even though L is not modified, we pass L by reference because frequently it will be a big structure and we don't want to waste time copying it.
† Making the header a complete cell simplifies the implementation of list operation in Pascal. We can use pointers for headers if we are willing to implement our operations so they do insertions and deletions at the beginning of a list in a special way. See the discussion under cursor-based implementation of lists in this section.
† Of course, there are many situations where we would like p to continue to represent the position of c.
† Incidentally, it is common practice to make the header of a doubly linked list be a cell that effectively "completes the circle." That is, the header's previous field points to the last cell and next points to the first cell. In this manner, we need not check for nil pointers in Fig. 2.14.
† Note that "consecutive" must be taken in circular sense. That is, a queue of length four could occupy the last two and first two positions of the array, for example.
† For example, firstvalue = 'A' and lastvalue = 'Z' if domaintype is 'A'..'Z'.
† In the "real" knapsack problem, we are given utility values as well as weights and are asked to maximize the utility of the items carried, subject to a weight constraint.
‡ Alternatively, x could be passed by reference if y is x.